Chapter 9
추론 최적화: Inference Optimization
- 모델을 더 나은 성능으로, 더 저렴하게, 더 빠르게 만드는 것은 항상 중요
- 추론 최적화는 모델, 하드웨어, 서비스 레벨에서 가능
- AI 추론의 병목과 이를 극복하기 위한 기술 설명
- 종종 모델을 빠르게 만드는 건 비용도 줄이도록 함
추론 최적화 이해하기
- AI 모델의 생애 주기는 훈련과 추론의 구분된 시기를 지님
- 훈련: 모델을 만드는 과정
- 추론: 주어진 입력으로부터 출력을 계산하는 과정
추론 개요
- 추론 서버inference server: 서비스 상황에서 모델 추론을 수행하는 주체
- 모델 개발이 의미를 가지는 때는 \(T <= p \times N\), 즉 훈련 비용보다 추론을 통한 수입이 많을 때
- 모델을 직접 운영하면 추론 서비스를 직접 만들고, 최적화하고, 유지보수해야함
계산 병목Computational bottlenecks
- 최적화는 병목을 찾고 해결하는 과정
- 2가지 주요 계산 병목
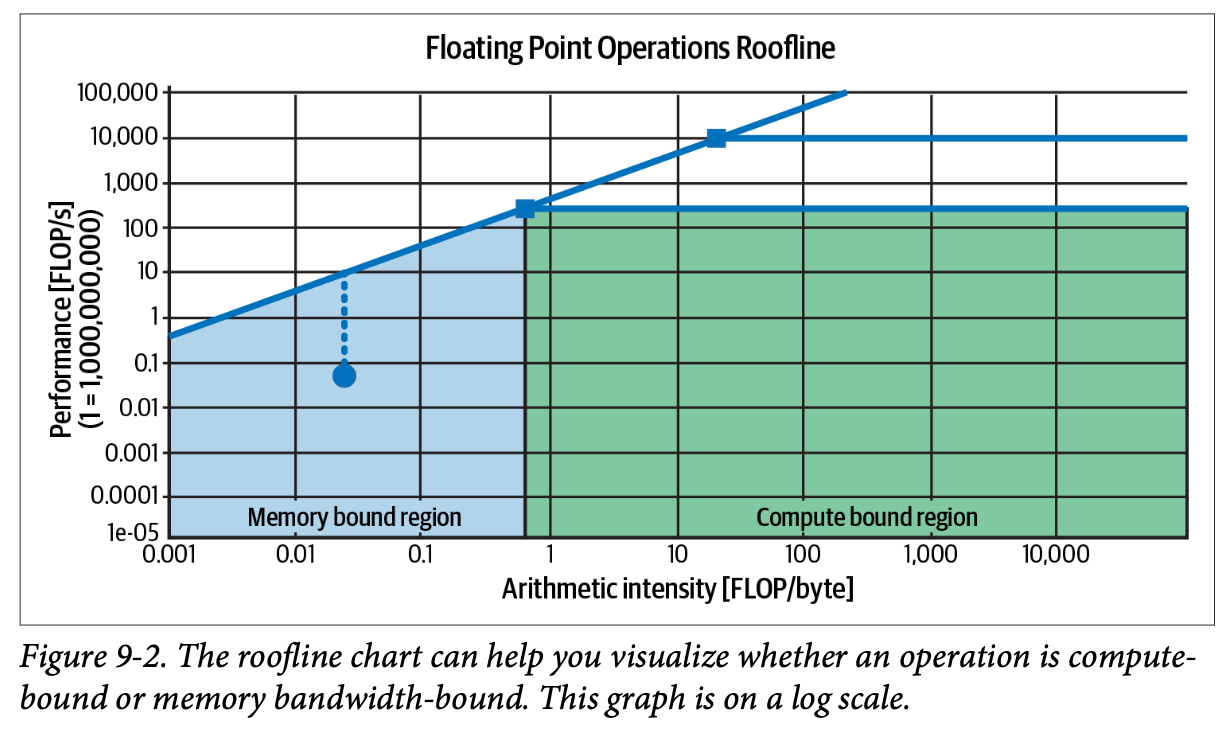
- 연산Compute-bound: 작업 완료 시간이 작업에 필요한 연산량에 의해 결정
- 메모리 대역폭Memory bandwidth-bound: 작업 완료 시간이 데이터 전송률(e.g. 메모리와 프로세서 간 데이터 이동)에 제한. 데이터를 CPU에서 GPU로 옮기는 건 많은 시간이 소요될 수 있음. bandwidth-bound로 줄이기도 함
- Memory-bound는 메모리 용량을 의미할 때도 있는데, OOM과 같은 문제로 나타남. 보통 이는 작업을 작은 단위로 분리하여 해결할 수 있음. 대부분의 메모리 관련 제한은 메모리 대역폭에 의함.
- 연산 병목은 더 많은 칩(수평 확장) 또는 연산 능력이 더 큰 칩(수직 확장)을 사용함으로써 해결 가능
- 메모리 대역폭 병목은 더 큰 대역폭을 가진 칩(수직 확장)을 사용함으로써 해결 가능
- Stable Diffusion 같은 이미지 생성기는 대개 연산 병목을 지님
- 자기회귀적 언어 모델은 대개 메모리 대역폭 병목을 지님
- 트랜스포머 기반 언어 모델은 2가지 단계로 구성됨: prefill, decode (Chapter 2)
- Prefill: 모델이 입력 토큰을 병렬로 처리하는 과정. 계산 병목을 지님
- Decode: 모델이 한 번에 하나의 출력 토큰을 생성하는 과정. 모델 가중치와 같은 대형 행렬을 불러오는 단계를 포함하여 하드웨어가 얼마나 빠르게 메모리에 데이터를 불러오는가에 제한을 받음. 메모리 대역폭 병목을 지님
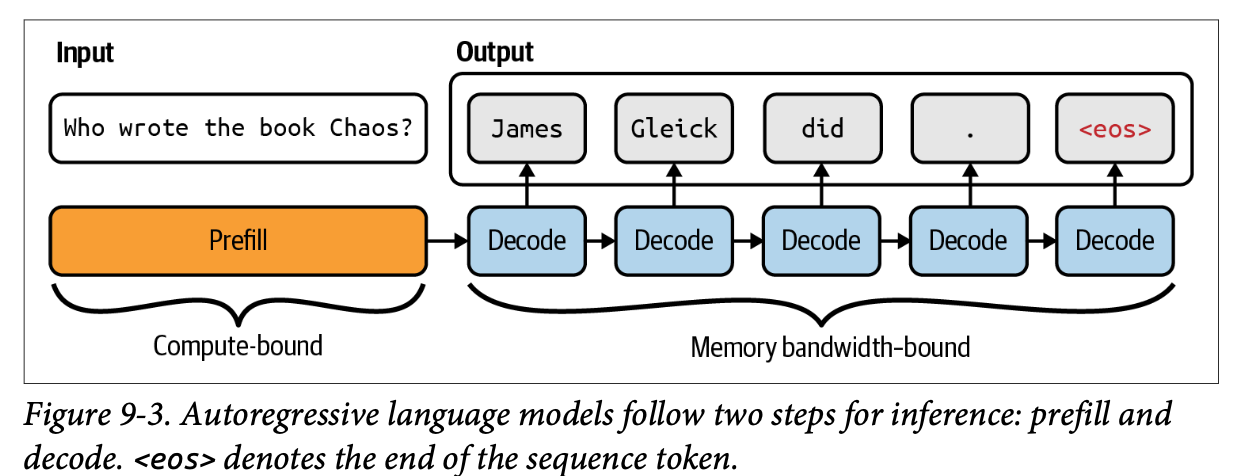
- 실제 서비스에선 prefill과 decode가 별개 장비로 분리 실행되는 경우가 많음
- LLM 병목에 영향을 주는 요소는 컨텍스트 길이, 출력 길이, 요청 배치 전략이 있음
- 긴 컨텍스트는 대개 메모리 대역폭 병목 작업부하를 일으킴
추론 API: 온라인과 배치Online and batch inference APIs
- 온라인 APIOnline APIs: 지연 시간을 최적화. 낮은 지연 시간에 집중.
- 배치 APIBatch APIs: 비용을 최적화. 높은 처리량throughput에 집중.
- 전통적 ML에서 배치 추론은 LLM과 의미가 다른데, 요청 전 예측을 미리 계산하는 과정을 의미. 추천 시스템에서 미리 모든 사용자의 추천을 생성해두는 것과 같은 예시가 있음.
추론 성능 지표
- 사용자 관점에서 중심축은 지연시간
- 비용 계산을 위해서는 처리량throughput과 사용량utilization도 중요
지연 시간, TTFT, TPOT
- 시간 지표 정의
- 지연 시간latency: 사용자 질의 전송 후 답변 전부를 수신하는데까지 걸린 시간
- TTFTTime to first token: 사용자 질의 전송 후 첫 토큰이 생성된 시간. prefill 과정의 소요 시간에 따르며 입력 길이에 의존함.
- TPOTTime per output token: 첫 토큰 이후 각 출력 토큰 생성 간 걸리는 시간. 스트리밍 모드에서 사람의 읽기 속도인 120 ms/token에 준하는 속도면 충분하므로, TPO는 120 ms 또는 6-8 tokens/s가 대부분의 용도에 충분함.
- TPOT을 희생하여 TTFT를 줄이려면 decode 연산 자원을 prefill 연산 자원으로 옮기는 것으로 가능
- 에이전트 질의는 중간 과정이 보이지 않아서 time to publish라는 첫 토큰의 사용자 노출 소요 시간을 의미하는 용어도 사용
- Anyscale 연구에 따르면 전체 지연 시간에 있어서 입력 토큰 100개는 출력 토큰 1개와 비슷한 영향도를 지님
- 지연 시간은 분포를 따르기 때문에, 평균보다 percentile을 확인하는 것이 유용함
- 이상점은 평균을 왜곡시킬 수 있고 흔히 발생함
- p50(중앙값), p90, p95, p99을 흔히 사용
- TTFT와 입력 길이의 관계를 도표화하면 유용
처리량과 유효 처리량Throughput and goodput
- 처리량throughput은 모든 사용자 및 요청에 대해 추론 서비스가 생성할 수 있는 초당 출력 토큰 수(tokens/s; TPS)를 측정
- 주어진 시간 동안 완전히 수행된 요청 수로 측정할 수 있음
- 파운데이션 모델의 생성 속도로 인해 대개 RPMrequests epr minute로 측정됨
- 처리량을 관찰하면 추론 서비스가 동시 요청을 얼마나 잘 다룰 수 있는지 이해하는데 도움이 됨
- 높은 처리량은 대개 낮은 비용을 의미함
- 일관된 입력 및 출력 길이를 가진 작업 부하의 경우 최적화가 더 쉬움
- 비슷한 크기의 모델, 하드웨어, 작업 부하를 사용해도 토큰 구성과 토크나이저가 다를 수 있어서 직접 비교는 어려움
- 추론 서버 효율은 요청 당 비용 지표를 이용하는 게 나음
- AI 앱은 지연 시간, 처리량 간 trade-off 관계가 있음
- 배치 같은 기술은 처리량을 향상시키지만 지연 시간을 늘림
- LinkedIn AI 팀, 2024에 다르면 처리량을 2, 3배 늘리려면 TTFT나 TPOT 희생이 필요한 경우가 많았음
- 유효 처리량goodput은 초당 SLO를 만족하는 요청의 수를 측정
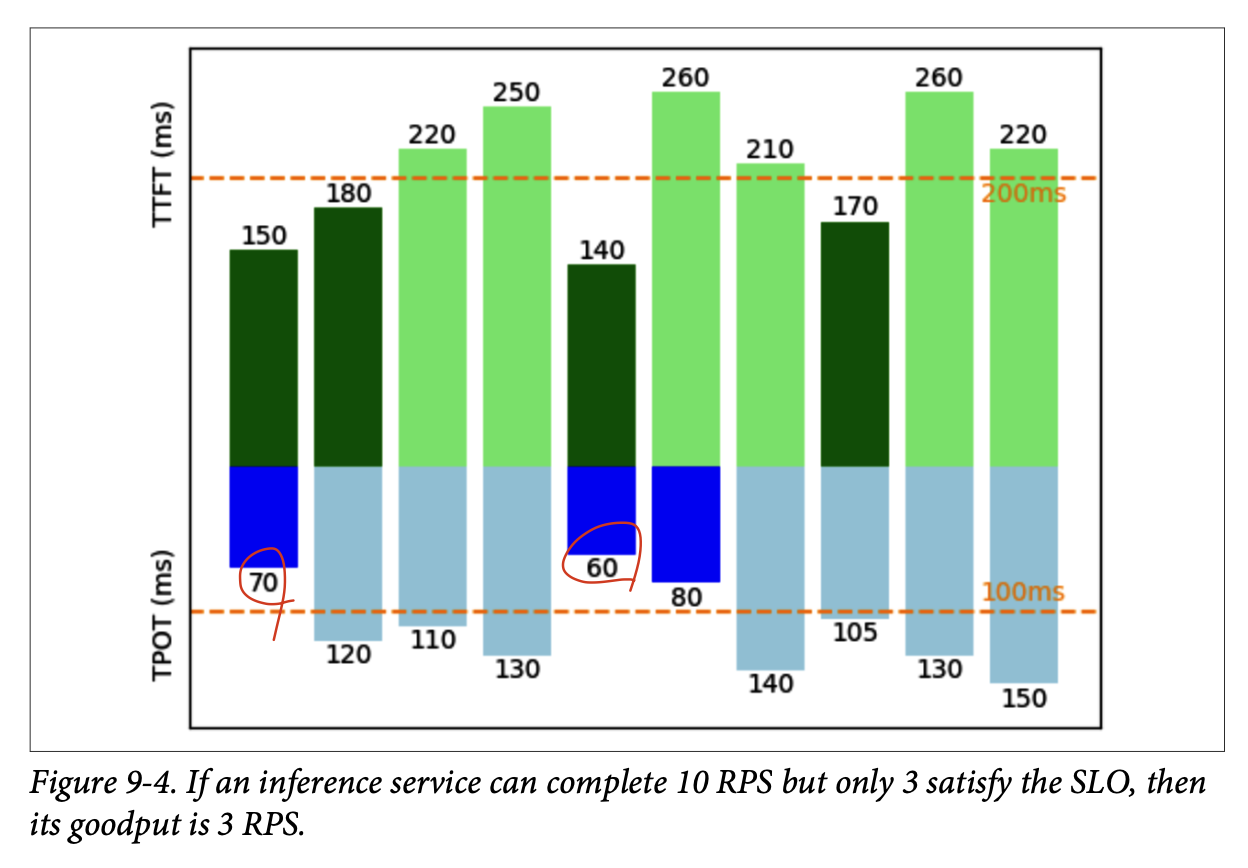
사용량, MFU, MBUUtilization, MFU, and MBU
- 사용량utilization은 자원이 효율적으로 이용되는 양을 측정. 주로 총 가용량에 비해 활성화된 자원의 비율로 정량화됨
- GPU utilization 용어는 오해하기 쉬움
- nvidia smi에서 나타내는 GPU utilization은 GPU가 활성화되어 작업을 처리하는 시간 비율을 의미함
- GPU가 100op/s를 처리할 수 있어도 1op/s를 처리하는 GPU는 nvdia-smi의 GPU Utilization 정의에 따라 100%로 나타날 수 있음
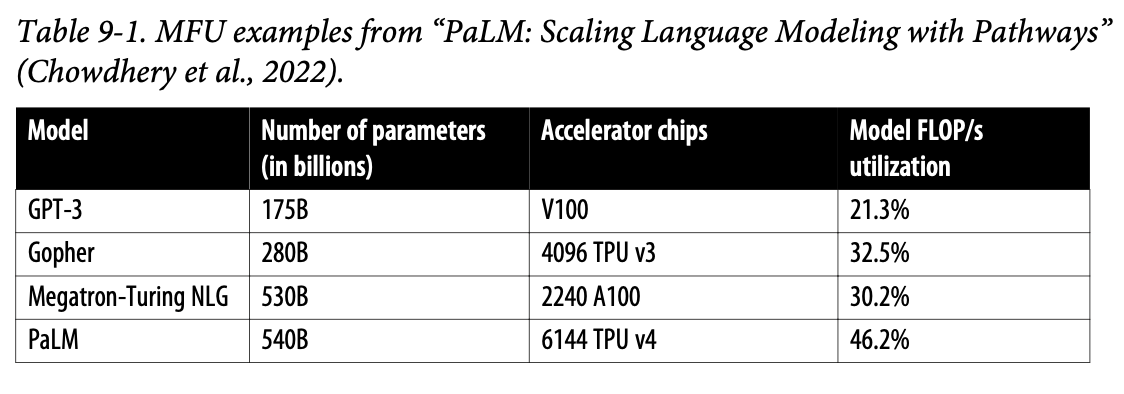
- MFUModel FLOP/s Utilization: 최대 FLOP/s로 가동되는 시스템의 이론적 최대 처리량에 비해 관찰된 처리량(tokens/s)의 비율
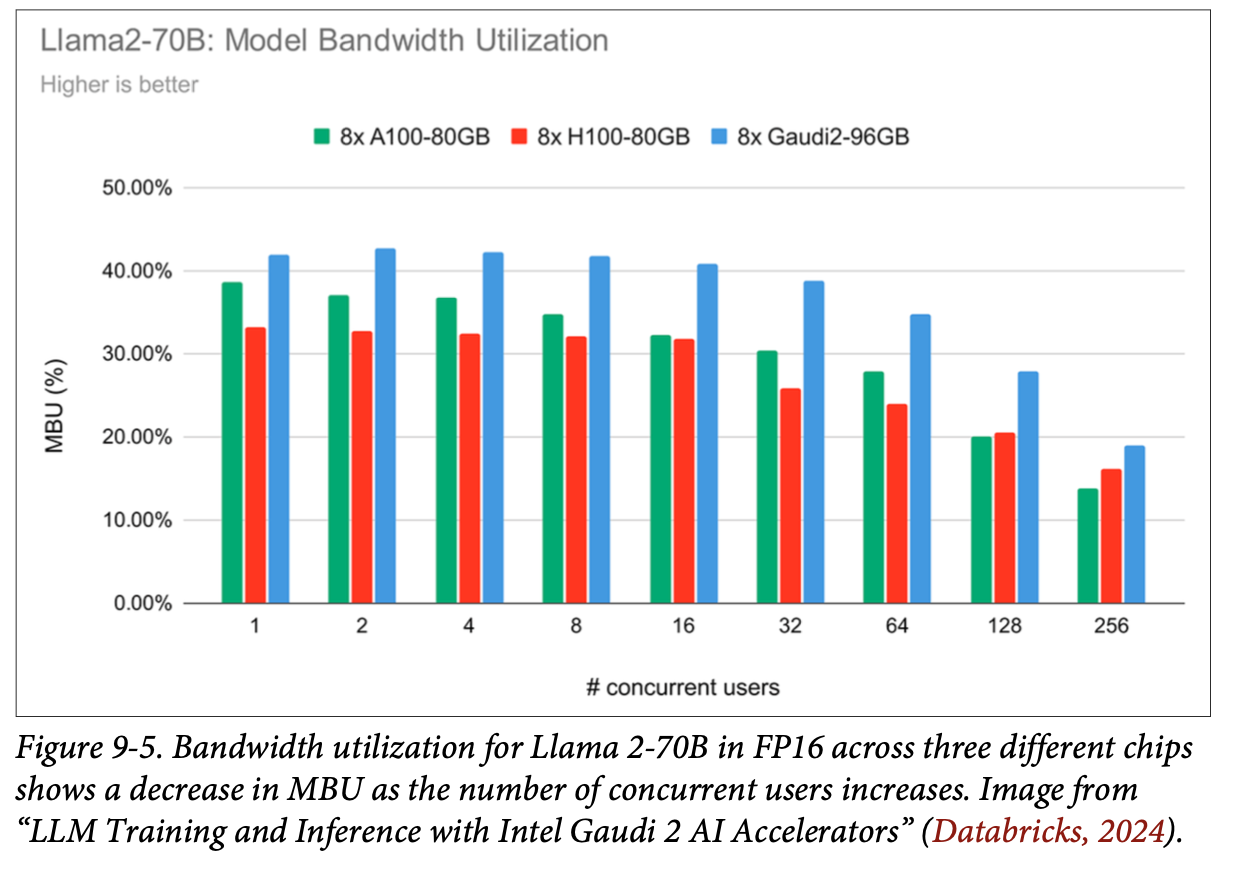
- MBUModel Bandwidth Utilization: 메모리 대역폭 사용 비율
- LLM의 메모리 대역폭 사용량 수식
- 메모리 대역폭 사용에 있어 파라미터당 bytes의 영향도로 인해 양자화가 중요함
- 처리량(tokens/s)과 MBU, 처리량과 MBU이 각각 비례하기 때문에 처리량을 MBU, MFU로 가늠할 수 있음
- 연산 병목 작업 부하는 MFU가 높고 MBU가 낮은 경향
- 메모리 병목 작업 부하는 MFU가 낮고 MBU가 높은 경향
- MFU는 대개 훈련 시가 추론 시보다 높음
- 추론에서 prefill이 연산 병목, decode가 메모리 병목을 지니기 때문에 prefill의 MFU는 decode보다 높음
- 현재로서는 50% 초과의 MFU는 좋은 수치
- 사용량Utilization 지표는 시스템 효율성 측정에 도움을 줌
- 최고의 사용량을 지닌 칩을 구매하는게 목표가 아님. 작업을 빠르게 저렴하게 하는게 목표. 높은 사용량 비율은 비용과 지연 시간이 모두 증가하면 의미가 없음
AI 가속기
추론 최적화
- 추론 최적화는 모델, 하드웨어, 서비스 수준에서 수행할 수 있음
- 이상적으로 모델의 품질에 변화없이 속도와 비용을 최적화해야하지만, 많은 실제 기술들은 모델 품질 저하를 유발할 수 있음
모델 최적화
- 모델 수준 최적화는 모델 자체를 수정해 효율적으로 만드는 것이 목표
- 파운데이션 모델을 주로 트랜스포머 아키텍처를 따르고, 자기회귀적 언어 모델 요소를 지님
- 파운데이션 모델을 자원 집약적으로 만드는 특징 3가지
- 모델 크기model size
- 자기회귀적 디코딩autoregressive decoding
- 어텐션 메커니즘attention mechanism
모델 압축
- 모델 압축: 모델 크기를 줄여서 속도를 빠르게 만드는 기술들
- 양자화quantization: 정밀도를 줄여 메모리 발자국을 감소시키고 처리량을 증가시키는 방법
- 증류distillation: 작은 모델이 대형 모델의 행동을 모방하도록 훈련시키는 방법
- 가지치기pruning은 2가지 의미</mark>
- 필요없는 노드를 신경망에서 제거. 아키텍처를 변화시키고 파라미터 수를 줄임
- 예측에 덜 사용되는 파라미터를 0으로 설정. 총 파라미터 수를 줄이지 않고 모델을 희박하게sparse만들어 모델의 저장소 사용량을 줄이고 연산을 빠르게 만듦
- 가지치기된 모델은 그대로 사용되거나 추가 파인튜닝될 수 있음. 파인튜닝은 가지치기 과정에서 유발된 성능 저하를 조정하기 위함
- 가지치기된 아키텍처는 이전보다 작기 때문에 밑바닥부터from scratch 훈련될 수 있음
- Frankle and Carbin, 2019은 가지치기로 0이 아닌 파라미터 수를 90% 줄여 메모리 발자국을 줄이고, 속도는 증가시키며, 정확도는 크게 변화시키지 않는 연구를 보임
- 가지치기는 현실에서는 덜 사용되는 방법. 다른 방법에 비해 성능 향상이 훨씬 적고, 드묾sparsity으로 이점을 가질 수 있는 하드웨어 아키텍처가 한정적이기 때문
- 가중치만 양자화weight-only quantization이 훨씬 인기있는 방법. 사용하기 쉽고, 많은 모델에 적용할 수 있고, 극적으로 효과적이기 때문
자기회귀적 디코딩 병목 극복하기
- 자기회귀적 과정은 느리고 비쌈
추측적 디코딩Speculative decoding
- 추측적 디코딩Speculative decoding은 더 빠르지만 덜 강력한 모델을 사용하여 토큰의 시퀀스를 생성한 후, 이를 목표 모델에 의해 검증하는 방식. speculative sampling이라고도 함
- 빠른 모델은 초안 또는 제안draft or proposal 모델로 불림
- 초안 모델이 K 토큰을 생성, 목표 모델이 생성된 K 토큰을 병렬적으로 검증함. 목표 모델이 초안 토큰의 가장 긴 부분 시퀀스를 수용함
- 현대 파이프라인된 CPU의 분기 예측과 유사
- Stern et al., 2018의 도표
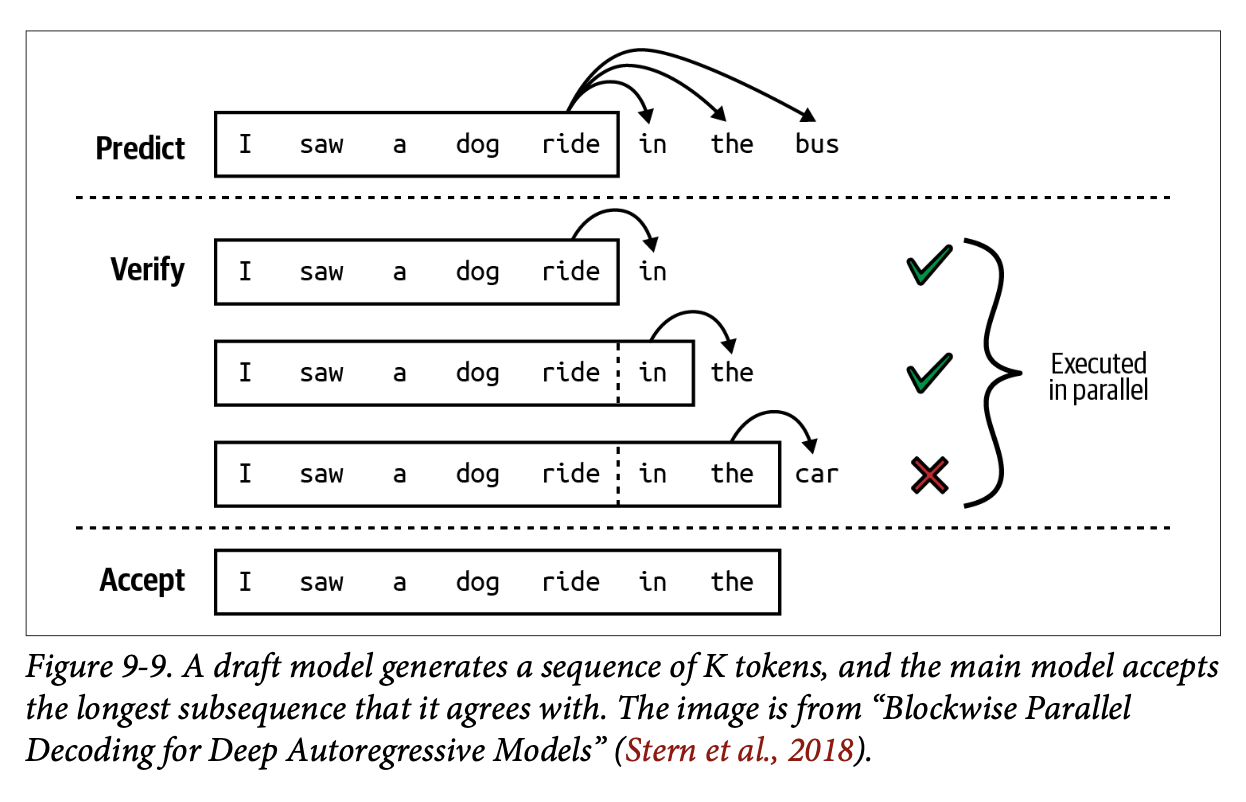

- Google’s AI overview, Fast Inference from Transformers via Speculative Decoding
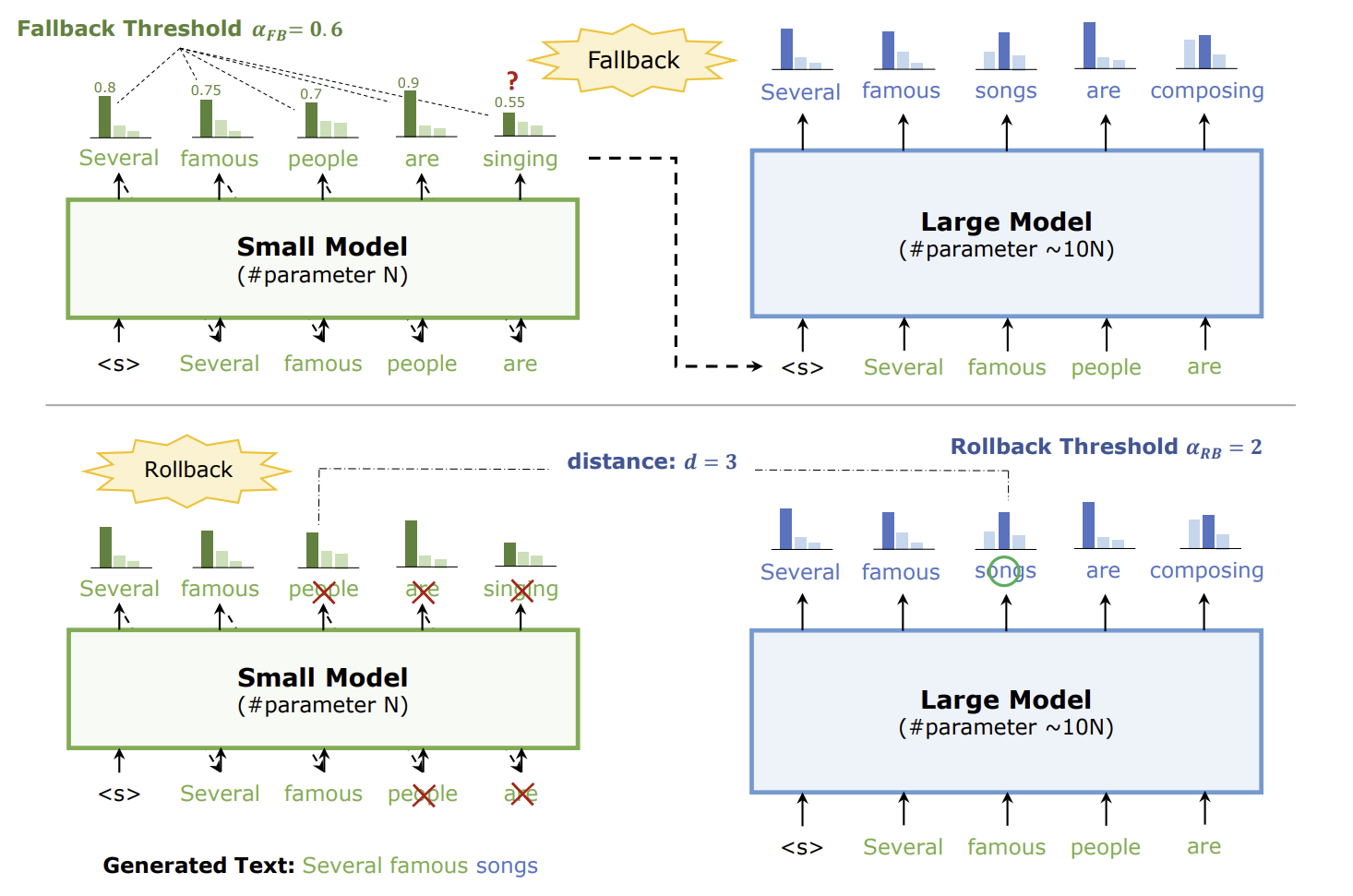
- 추측적 디코딩이 추가 지연 시간을 줄일 수 있는 특징:
- 토큰 시퀀스 검증은 병렬화될 수 있고, 생성은 직렬적임. 추측적 디코딩은 디코딩을 prefilling으로 연산 특성을 바꿈
- 출력 토큰 시퀀스에서 어떤 토큰을 예측하기 더 쉬움. 약한 초안 모델도 예측하기 쉬운 토큰을 잘 생성하므로 수용률이 높아질 수 있음.
- 디코딩은 메모리 대역폭 병목을 지니므로 남는 FLOPs로 검증(prefill처럼)을 수행할 수 있음
- 수용률은 도메인 의존적. 특정 구조를 따르는 코드와 같은 경우 수용률이 대개 높음.
- vLLM, TensorRT-LLM, llama.cpp에서 지원함
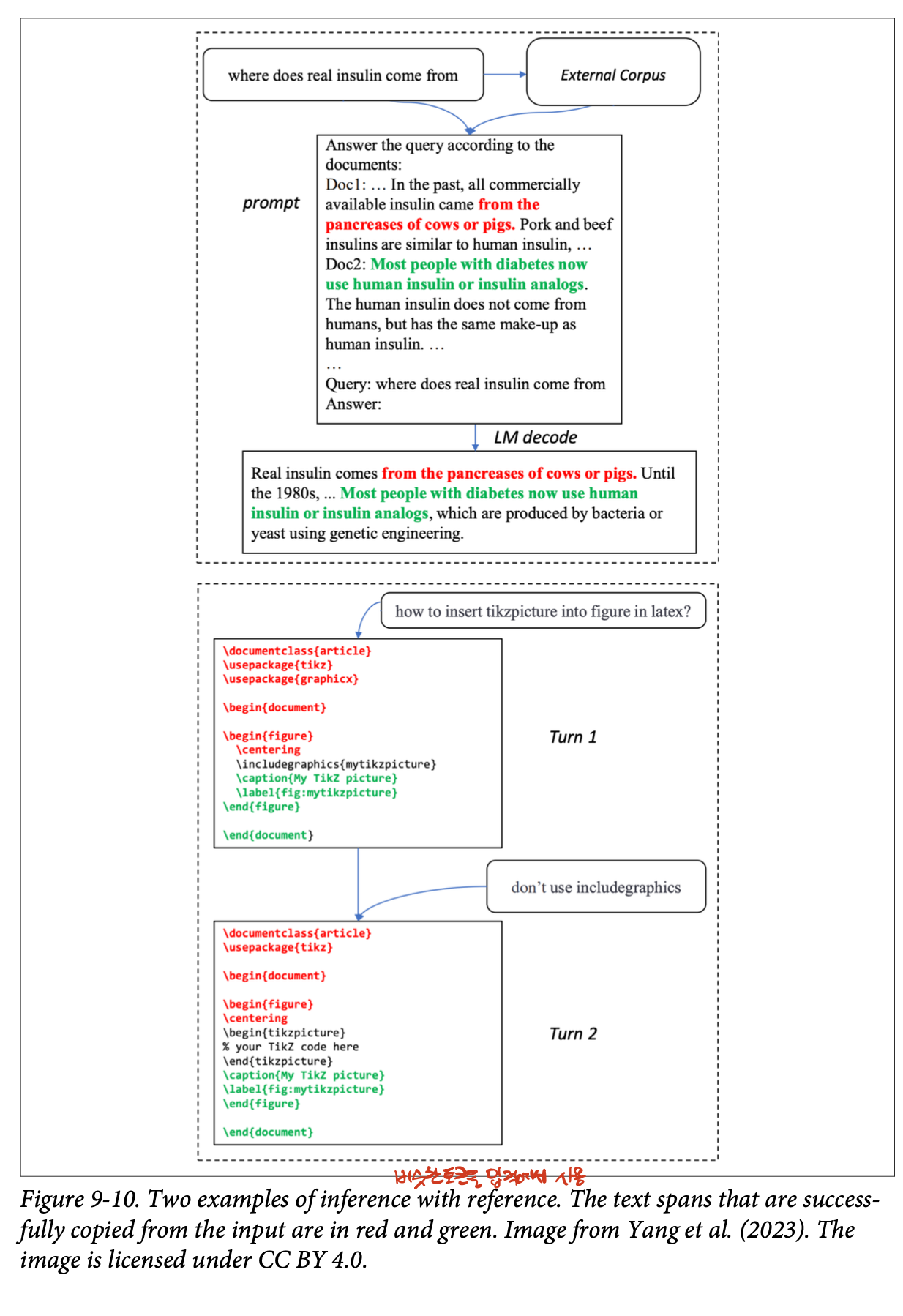
인용을 통한 추론Inference with reference
- 추측적 디코딩과 유사하지만, 초안 토큰을 입력에서 선택하는 점이 다름
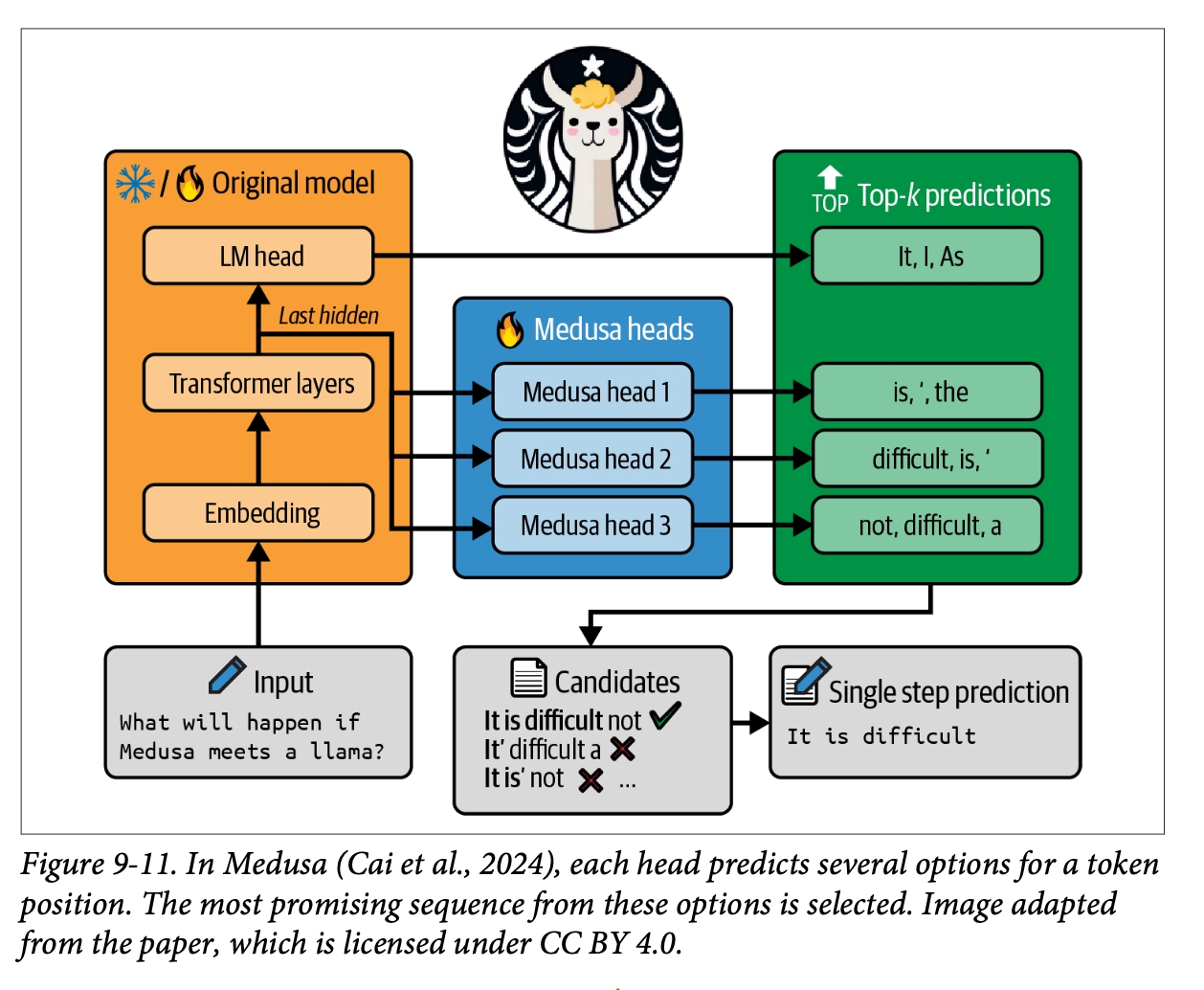
병렬 디코딩Parallel decoding
- 존재하는 토큰 시퀀스에 대해 한 개가 아닌 여러 토큰을 동시에 예측하는 방법
- Medusa (Cai et al., 2024)는 다수의 디코딩 헤드를 확장해 각 헤드에 작은 신경망 모델을 더해 특정 위치의 미래 토큰을 예측하도록 훈련함.
- 원본 모델은 고정한채, 새로운 신경망만 학습
- Llama 3.1 토큰 생성을 1.9배 빠르게 함
- 생성된 토큰들은 검증 및 통합되어야 함
- 미래 토큰 K개 병렬로 생성
- 토큰 K개에 대해 컨텍스트에 대한 문맥적, 논리적 일관성을 검증
- 하나 이상의 토큰이 검증 실패하면, 모델이 재생성하거나 실패한 토큰만 조정함
- Lookahead 디코딩은 Jacobi method를 사용해 생성된 토큰을 검증함
- 모델은 모든 토큰이 검증을 통과할때까지 정제하고, 그 후 최종 출력에 통합됨
- 이러한 병렬 디코딩 알고리즘을 Jacobi decoding이라고 함
- Medusa는 트리 기반 어텐션 메커니즘 사용
어텐션 메커니즘 최적화
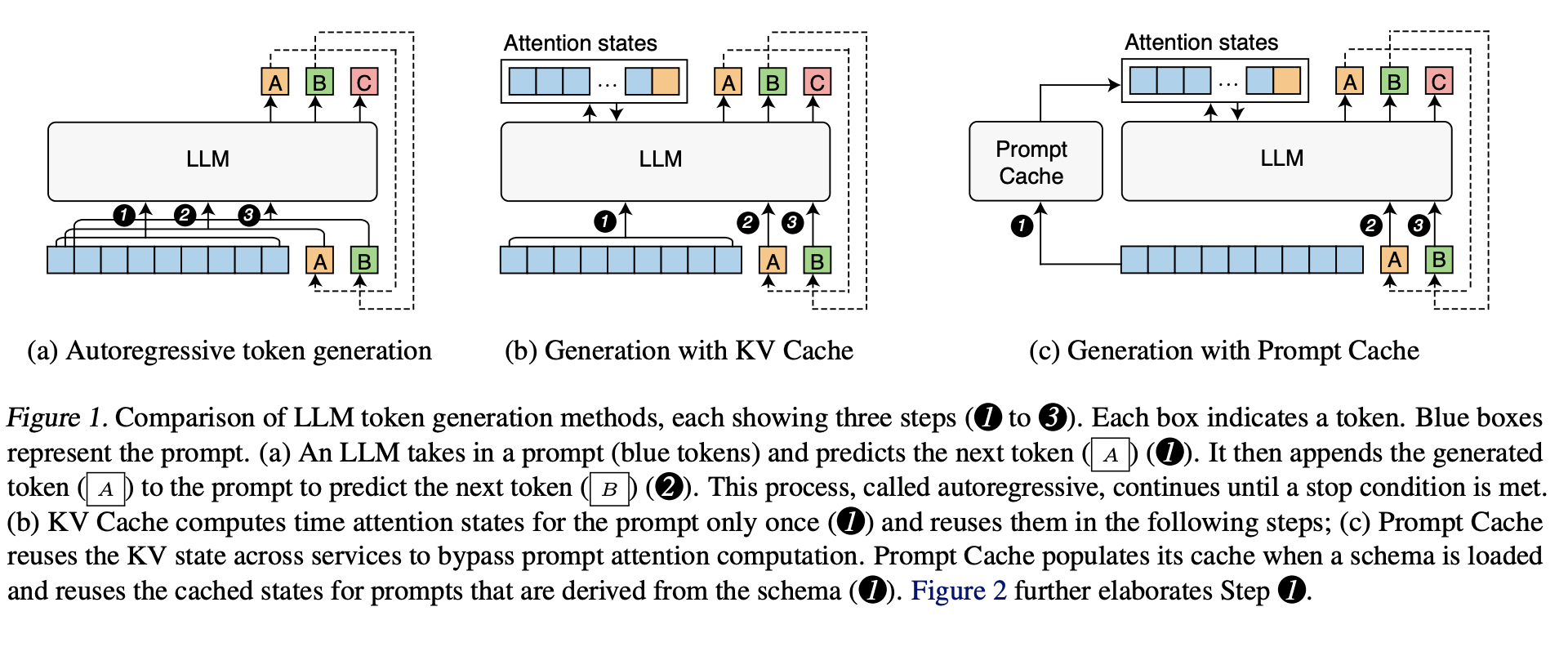
- KV cache: KV 행렬을 매 입력마다 계산하지 않고 이전 계산값을 저장. 새롭게 계산된 KV 벡터는 KV Cache에 추가됨
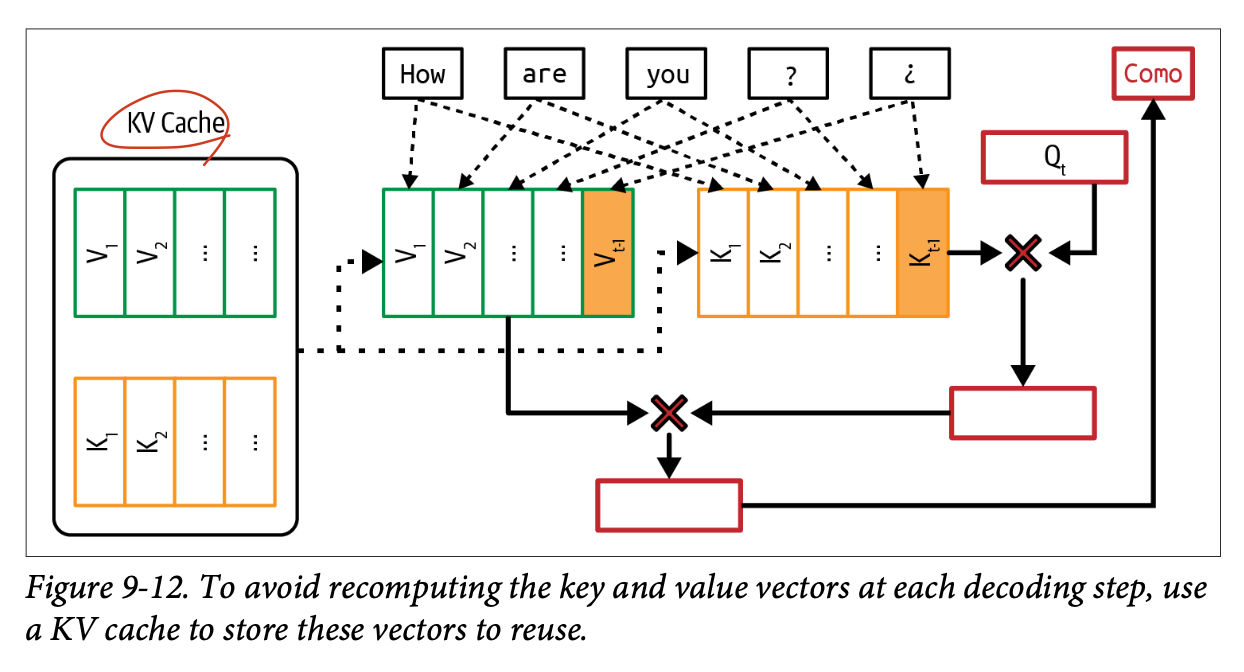
- KV 캐시는 추론에만 사용됨
- KV 캐시는 시퀀스 길이에 따라 선형 증가함. 어텐션 연산량은 다항함수적으로 증가(n^2 등)
- 어텐션 메커니즘의 연산 및 메모리 요구량이 긴 컨텍스트를 가지기 어려운 원인
- 어텐션 메커니즘을 효율적으로 만드는 3가지 방법
- 어텐션 메커니즘 재설계
- KV 캐시 최적화
- 어텐션 연산 커널 작성
어텐션 메커니즘 재설계
추론 서비스 최적화
배치Batching
프리필과 디코딩 분리Decoupling prefill and decode
프롬프트 캐싱Prompt caching
- 프롬프트 캐시는 중복된 문구를 재사용을 위해 저장
- 컨텍스트 캐시, prefix 캐시라고도 불림
- Prompt Cache: Modular Attention Reuse for Low-Latency Inference
병렬화
- 2가지 종류: 데이터 병렬화, 모델 병렬화
- LLM 병렬화: 컨텍스트 및 시퀀스 병렬화
- 레플리카 병렬화: 가장 구현 간단
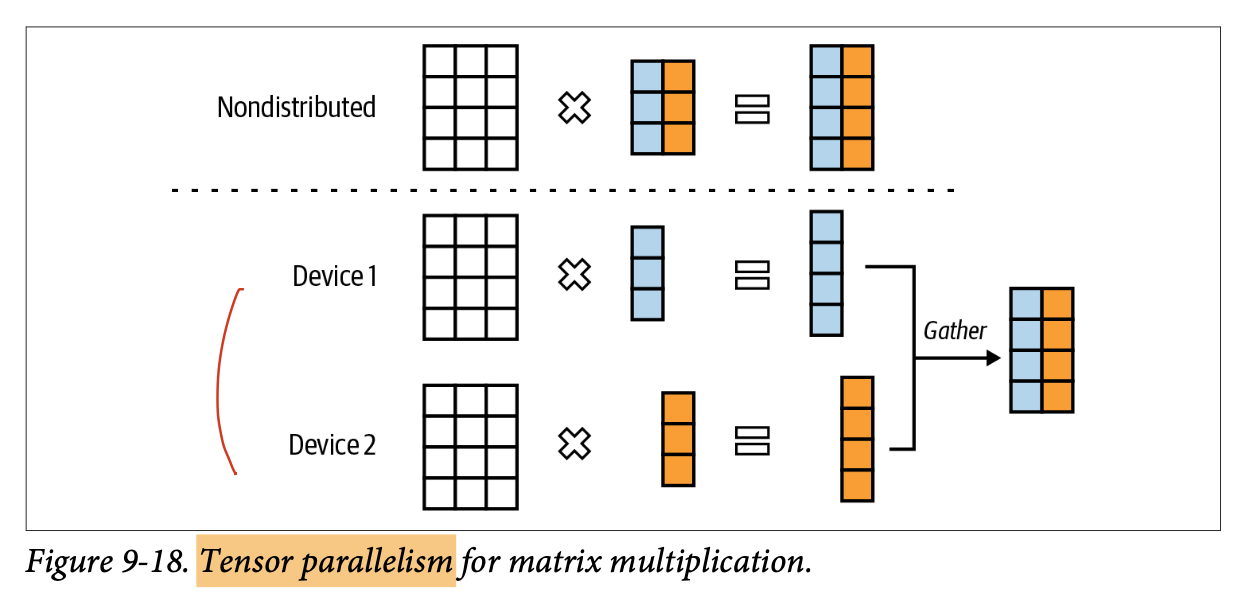
- 모델 병렬화: 동일 모델을 여러 장비로 분할하는 관행을 의미. 대표적인 방법이 텐서 병렬화
- 텐서 병렬화(오페레이터 내 병렬화): 오퍼레이터 내 텐서를 분할하여 여러 장비에서 나누어서 연산
두 가지 장점을 지님:- 단일 장비로 서빙하기 어려운 대형 모델 서빙 가능
- 지연 시간 감소. 추가적인 커뮤케이션 오버헤드로 효과가 적을 수 있음
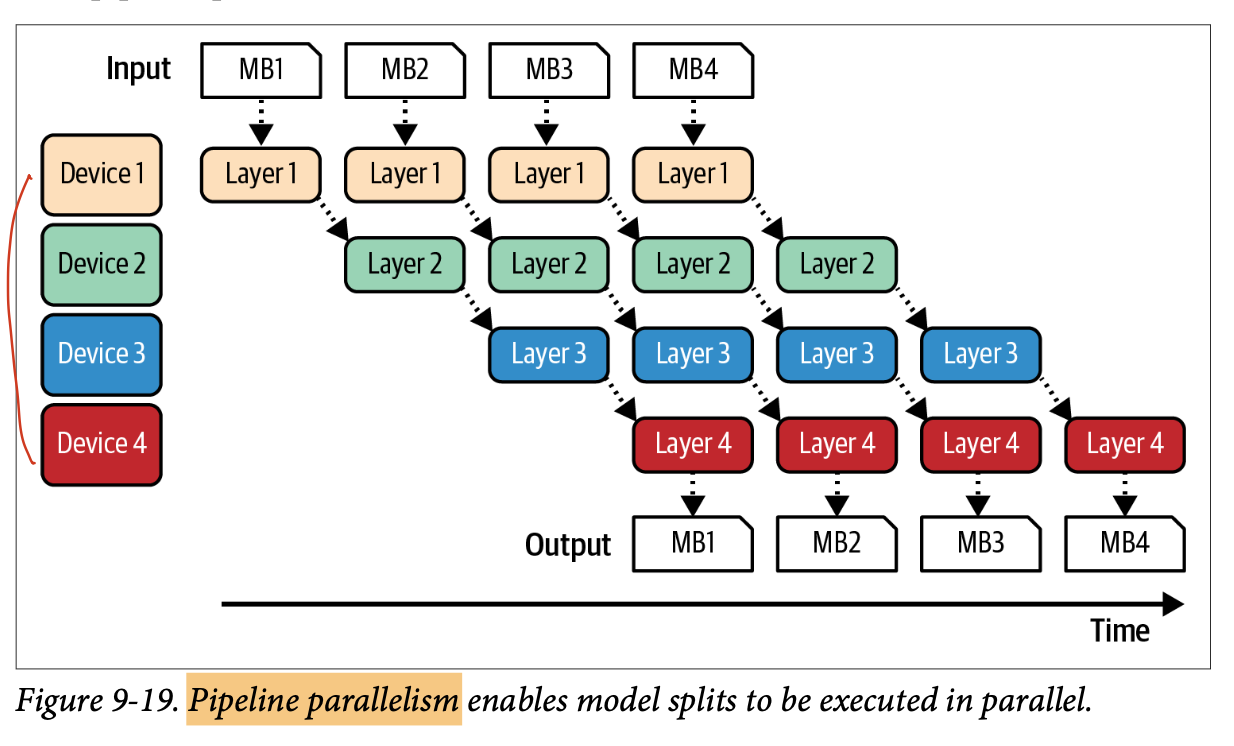
- 파이프라인 병렬화
Chapter 10
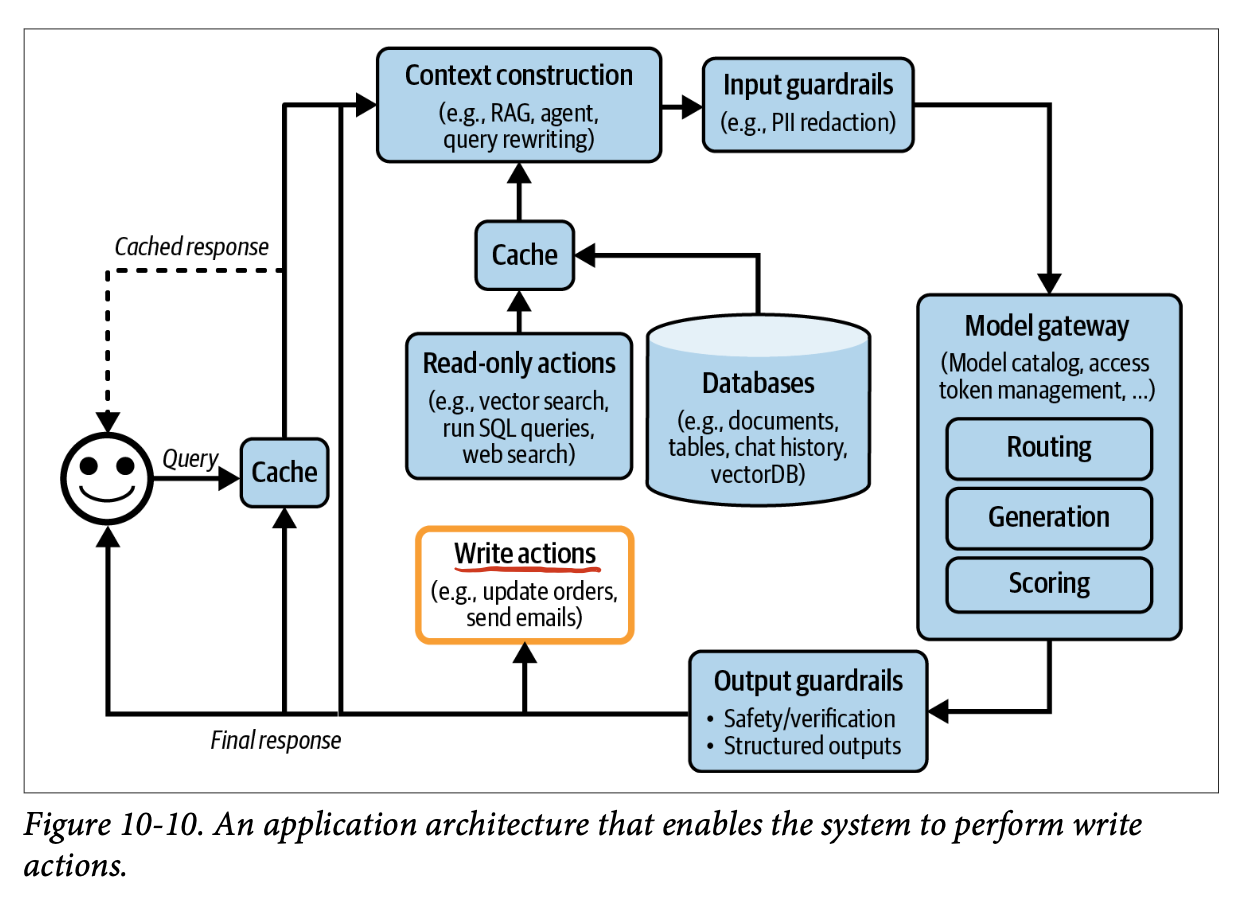
AI 엔지니어링 아키텍처와 사용자 피드백: AI Engineering Archiecture and User Feedback
AI 엔지니어링 아키텍처AI Engineering Architecture
1단계. 컨텍스트 개선
2단계. 보호 장치 마련Put in Guardrails
3단계. 모델 라우터와 게이트웨이 추가Add Model Router and Gateway
4단계. 캐시로 지연 시간 축소
5단계. 에이전트 패턴 추가