Chapter 7
Finetuning: 파인튜닝
- 파인튜닝은 모델의 전체 또는 일부를 추가적으로 학습시켜서 특정 작업에 적응adapt시키는 과정을 말한다.
- 모델의 가중치를 조정한다.
- 모델의 도메인 특화 기능을 향상시킬 수 있다.
- 코딩이나 의학 질의응답
- 모델의 안전성을 강화할 수 있다.
- 대부분 모델의 지시 수행 능력을 향상시키는데 사용된다. 특히 특정 출력 스타일이나 형식에 준수하도록 하기 위해 활용된다.
- 언제 파인튜닝 또는 RAG를 해야할지는 흔한 질문이다.
- 프롬프트 기반 방법과 다르게 파인튜닝은 훨씬 많은 메모리 발자국을 유발한다.
- 많은 파인튜닝 기술들은 메모리 요구량을 줄이는 것에 착안하여 개발됐다.
- PEFTparameter-efficient finetunig는 메모리 효율적인 접근으로 파인튜닝 영역에서 지배적이되었다.
- PEFT에서는 특히 adpater-based 기술을 살펴본다.
파인튜닝 개요
- 파인튜닝은 필요한 능력을 가진 베이스 모델로 시작한다.
- 파인튜닝의 목표는 베이스 모델을 특정 작업을 더 잘 수행하도록 만드는 것이다.
- 파인튜닝은 전이 학습transfer learning의 한 방법이다.
- 전이 학습은 Bozinov‐ski와 Fulgosi에 의해 1976년 처음 소개되었다.
- 전이 학습은 한 작업에서 얻어진 지식을 새로운 작업의 학습 가속을 위해 전이하는 방법에 집중한다.
- 피아노를 칠 줄 아는 사람이 다른 악기를 더 쉽게 다루는 것과 비슷하다.
- 딥러닝 초창기 동안 전이 학습은 제한되거나 값비싼 훈련 데이터를 지닌 작업에 대한 해결책을 제시했다.
- LLM에서 텍스트 완성을 위한 사전 학습에서 얻어진 지식은 특화된 작업인 법률 질의응답이나 text-to-SQL로 전이될 수 있다.
- 전이 학습의 능력은 파운데이션 모델을 더 가치있게 만들 수 있다.
- 전이 학습은 샘플 효율성sample efficiency를 향상시키고 모델은 더 적은 예제로 같은 행동을 효과적으로 배우게 할 수 있다.
- 예를 들어, 법률 질의응답 모델을 처음부터 만드려면 100만개의 예제가 필요하겠지만, 좋은 베이스 모델을 파인튜닝할 때는 수백개의 예제로 충분하다.
- 이상적으로 보면, 모델이 배워야 할 많은 내용은 이미 베이스 모델에 포함되어 있으며, 파인튜닝은 모델의 행동을 다듬는 역할을 한다.
- OpenAI의 InstructGPT (2022)에서는 모델이 이미 가지고 있으나 사용자들이 프롬프팅만으로는 접근하기 어려운 능력을 파인튜닝이 잠금 해제한다는 관점을 제안한다.
- 파인튜닝은 모델 학습 과정의 일부이며, 사전 학습의 확장이다.
- 파인튜닝은 사전 학습 이후의 모든 훈련을 의미한다.
- 모델 훈련 과정은 사전 학습으로 시작되며 자기 지도self-supervision로 이루어진다.
- 자기 지도는 모델이 레이블되지 않은 다량의 데이터로부터 학습할 수 있도록 한다.
- 언어 모델에서 자기 지도 데이터는 주석이 필요없는 텍스트의 나열을 의미한다.
- 값비싼 작업 특화 데이터로 파인튜닝하기 전에, 저렴한 작업 연관 데이터로 자기 지도 파인튜닝을 할 수 있다.
- 예를 들어, 법률 질의응답의 경우 날 것의 법률 문서로 파인튜닝할 수 있다.
- 모델이 베트남어로 책 요약을 하도록 파인튜닝하려면 많은 베트남어 텍스트로 먼저 인튜닝할 수 있다.
- 자기 지도 파인튜닝self-supervised finetuning은 계속된 사전 학습continued pre-traning이라고도 불린다.
- 지도 파인튜닝supervised finetuning을 통해 모델이 다음 토큰이나 빈 칸을 채우도록 파인튜닝할 수 있다.
- 후자는 빈 칸 채우기 파인튜닝infilling finetuning이며 텍스트 편집이나 코드 디버깅 같은 작업에 특히 유용하다.
- 모델이 자기회귀적autoregressively으로 사전 학습되었더라도 빈 칸 채우기 파인튜닝을 할 수 있다.
- 지도 파인튜닝은 고품질의 주석이 달린 데이터를 사용하여 모델을 인간의 사용 방식과 선호도에 맞게 다듬는다.
- 지도 파인튜닝 동안 모델은 (입력, 출력) 쌍으로 훈련된다.
- 입력은 지시, 출력은 답변이 될 수 있다.
- 답변은 책 요약처럼 열린 결말open-ended이거나 분류 작업처럼 닫힌 결말close-ended일 수 있다.
- 고품질 지시 데이터는 만들기 어렵고 비쌀 수 있다. 특히 사실적 일관성, 도메인 전문가, 정치적 올바름을 요구하는 지시일 경우 더 그렇다.
- 모델은 사람의 선호도를 최대화할 수 있는 답변을 생성하도록 강화 학습으로 파인튜닝될 수 있다.
- 선호도 파인튜닝preference finetuning은 주로 (지시, 이긴 답변, 진 답변)의 형식을 따르는 비교 데이터를 필요로 한다.
- 컨텍스트 길이를 늘리기 위해 모델을 파인튜닝할 수 있다.
- 긴 컨텍스트 파인튜닝long-context finetuning은 주로 모델의 구조를 수정할 필요가 있다. 일례로, 위치 임베딩positional embedding을 조정해야 한다.
- 긴 시퀀스는 토큰이 더 많은 가능한 위치를 가진다는 것이고, 위치 임베딩은 이를 처리할 수 있어야 한다.
- 긴 컨텍스트 파인튜닝은 다른 파인튜닝보다 수행하기 어렵고, 결과 모델은 짧은 시퀀스에 대해 품질이 저하될 수 있다.
- 모델 개발자는 다른 목적으로 파인튜닝된 여러 모델 버전을 출시할 수 있으며, 애플리케이션 개발자는 적합한 모델을 선택할 수 있다.
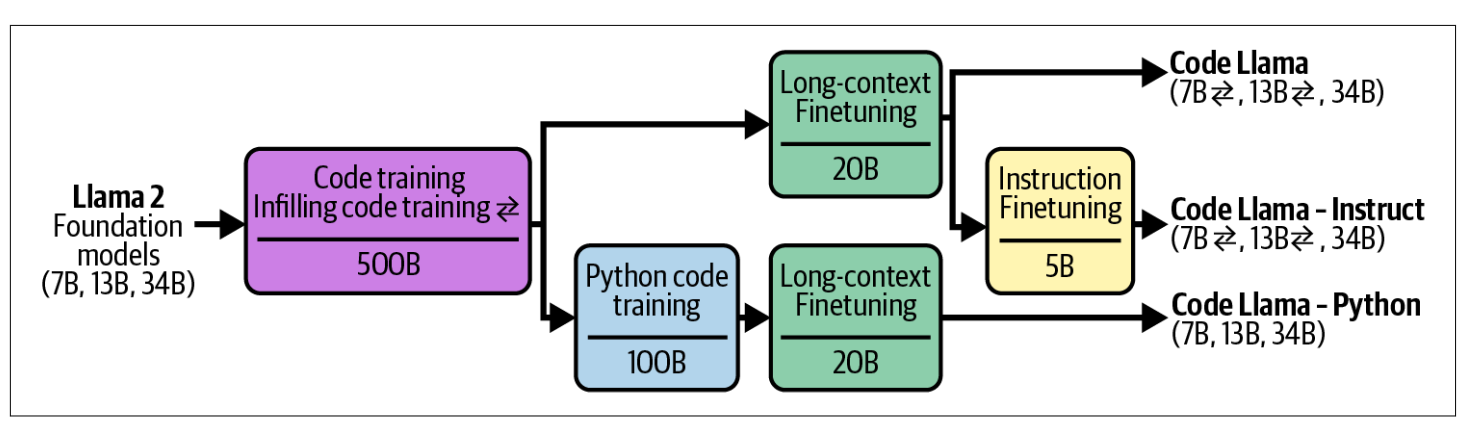
Code Llama 모델에 적용된 여러 파인튜닝 기술들
언제 파인튜닝을 해야할까?
파인튜닝과 프롬프팅은 상호 배타적인 접근이 아니라, 현실 세계의 문제를 풀기 위해 종종 함께 사용되어야 한다.
파인튜닝할 이유
-
파인튜닝할 주된 이유는 모델의 품질을 향상시키기 위함이다.
여기서 품질이란 전반적인 모델의 능력과 작업 특화적인 능력을 의미한다. - 특히 흥미로운 파인튜닝 용례는 편견 제거다. 베이스 모델이 훈련 데이터로부터 어떤 편견을 영속하고 있으면, 세심하게 선정된 데이터를 노출시키는 방식으로 파인튜닝을 진행하면 해당 편견을 상쇄시킬 수 있다.
- Garimella et al. (2022)는 여성이 작성한 글이 모델의 성별 편견을 제거하고, 아프리칸 작성자가 쓴 글이 인종 편견을 제거할 수 있음을 발견했다.
- 공통적인 접근 방법을 더 큰 모델로부터 생성된 데이터를 통해 더 큰 모델의 행동을 작은 모델이 모방하도록 파인튜닝하는 것이다.
- 증류distillation라는 방법으로 대형 모델의 지식을 작은 모델로 증류하는 접근 방법이다.
- 특정 작업에 대해 파인튜닝된 작은 모델은 가끔 훨씬 큰 초기 상태의 모델보다 해당 작업을 잘 수행할 수 있다.
파인튜닝하지 않을 이유
- 파인튜닝은 모델의 성능을 향상시킬 수 있지만 섬세하게 작성된 프로픔프트와 컨텍스트도 성능 향상에 기여할 수 있다.
- 먼저, 모델을 특정 작업에 파인튜닝하면 해당 작업에 대한 성능을 향상시킬 수 있지만, 다른 작업에 대한 성능을 약화시킬 수 있다.
이런 경우 서로 다른 작업에 분리된 모델을 사용하는 것을 고려해볼 수 있다.
- 프로젝트를 위한 실험의 시작으로 파인튜닝을 사용하기는 어렵다. 파인튜닝에는 먼저 데이터가 필요하고, 주석처리된 데이터는 수동으로 얻기에 느리고 비싸다. 특히 비판적 사고와 도메인 전문 지식을 요구하는 작업의 경우 더 그렇다. 오픈 소스 데이터와 AI로 생성된 데이터가 비용을 줄여줄 수 있지만, 그 효과성은 매우 변동적이다.
- 두번째로, 파인튜닝은 모델을 훈련하는 방법에 대한 지식을 필요로 한다.
- 세번째로, 모델을 파인튜닝했다면 어떻게 서빙해야할지 결정해야한다.
- 모니터링, 유지보수, 모델 업데이트에 대한 정책과 예산을 수립해야한다.
베이스 모델은 당신이 파인튜닝한 모델을 개선하는 속도보다 빠르게 개선될 수 있다.
- 모니터링, 유지보수, 모델 업데이트에 대한 정책과 예산을 수립해야한다.
- 많은 경우에 나은 모델로 교체하는 것은 성능 향상에 있어 매우 작은 부분만 제공한다.
- AI 엔지니어링 실험은 프롬프팅으로 시작되어야 한다.
- 모델의 성능은 서로 다른 프롬프트에 따라 매우 크게 다를 수 있다.
- 프롬프트가 비효율적이라고 주장하고 파인튜닝의 정당성을 주장한 많은 경우, 프롬프트 실험이 최소화되고 체계적이지 않았다. 지시가 불명확하고, 예제가 실제 데이터를 대표하지 않고, 지표가 어설프게 정의되었다. 프롬프트 실험 과정을 정교화하고나서는 프롬프트 품질이 해당 사례의 애플리케이션에 충분할 정도로 향상되었다.
- 파인튜닝을 주장하는 엔지니어 중 몇은 단지 파인튜닝을 배우고 싶은 경우가 있다.
- 리더십 위치라면 파인튜닝이 정말 필요한 것인지 단지 하고 싶은것인지 구별하기 어렵다.
- 파인튜닝과 프롬프트 실험 모두 체계적 과정이 필요하다. 프롬프트 실험을 수행하는 것은 개발자가 평가 파이프라인, 데이터 주석 가이드라인 및 실험 추적 관행을 구축할 수 있게 하며, 이는 파인튜닝을 위한 디딤돌이 될 것이다.
- 파인튜닝의 한가지 이점은 토큰 사용을 취적화하는데 도움이 된다는 것이다. 이는 프롬프트 캐싱이 소개되기전까지 유효했다.
- 매 프롬프트마다 예제를 포함하지 않고, 해당 예제들로 모델을 파인튜닝할 수 있다. 이는 파인튜닝한 모델을 더 짧은 프롬프트로 사용할 수 있게 한다.
- 프롬프트 캐싱을 사용하면, 반복적인 프롬프트 구문은 재사용을 위해 캐시될 수 있어서 강력한 이점이 되지는 못한다.
- 프롬프트에 제공할 수 있는 예제의 수는 최대 컨텍스트 길이에 제한된다.
- 파인튜닝을 이용하면, 사용할 수 있는 예제의 수에 제한이 없다.
파인튜닝과 RAG
- 프롬프트로부터 가능한 성능 향상을 최대화하고나서는 RAG나 파인튜닝 중 어떤 걸 시도할 지 고민할 수 있다. 이는 모델의 실패가 정보information-based 또는 행동behavior-based에 기인한 것인지에 따라 다르다.
- 모델이 정보 부족으로 실패한다면 모델이 연관 된 정보의 출처에 접근할 수 있도록하는 RAG 시스템이 도움을 줄 수 있다. 정보에 기인한 실패는 출력이 사실적으로 틀렸거나 기한이 지났을 경우 발생한다.
- 정보 부족
- 공개 모델은 당신 조직의 사적 정보를 포함하고 있지 않다.
- 기한 지난 정보
- Taylor Swift의 앨범수를 물어볼 경우 모델의 cut-off 날짜에 따라 다르게 응답할 수 있따.
- 정보 부족
- Fine-Tuning or Retrieval?에 따르면 최신 정보가 필요한 작업의 경우 파인튜닝 모델보다 RAG가 더 나은 성능을 보였다. 또한, 베이스 모델을 통한 RAG가 파인튜닝 모델을 통한 RAG보다 나은 성능을 보였다. 이는 파인튜닝은 특정 작업에 모델의 성능을 향상시킬 수 있지만, 다른 분야에 대한 성능을 약화시킬 수 있다는 것을 시사한다.
- 모델이 행동 문제가 있다면 파인튜닝이 도움이 될 수 있다.
- 행동 문제 예시는 모델의 출력이 사실적으로 맞지만 작업에 부적절한 경우다.
- 다른 문제는 예상한 출력 형식을 모델이 따르지 못하는 경우다.
- 의미적 파싱semantic parsing은 자연어를 JSON같은 구조화 형식으로 변환하는 걸 의미한다.
- 요약하자면 파인튜닝은 형식을 위해, RAG는 사실을 위해 실시한다.
- RAG 시스템은 모델에 외부 지식을 제공해 더 정확하고 정보가 풍부한 답변을 생성할 수 있게 한다.
- RAG 시스템은 모델의 할루시네이션 제거에 도움을 줄 수 있다.
- 파인튜닝은 모델이 문법과 형식을 이해하고 따를 수 있도록 하는 데 도움을 준다.
- 파인튜닝도 할루시네이션을 줄일 수 있다. 이는 데이터 품질이 좋을 때만이고, 저품질 데이터는 할루시네이션을 악화시킬 수 있다.
- 모델이 정보과 행동 문제를 모두 가지고 있다면 RAG으로 시작하라.
- RAG을 진행할 때, BM25 용어 기반 방법을 먼저 시도한다. 벡터 데이터베이스를 필요로하는 방법은 나중이다.
- RAG은 파인튜닝보다 더 큰 성능 향상을 가져올 수 있다.
- RAG와 파인튜닝은 상호 배타적이지 않고, 애플리케이션 성능의 최대화를 위해 함께 사용되기도 한다.
- Ovadia et al. (2024)는 파인튜닝 모델 위에 RAG를 사용하는 것은 MMLUE 벤치마크에서 성능 향상을 보인 경우를 포함한다.
- 57%의 경우 RAG만 사용한 경우에 비해 파인튜닝과 RAG를 함께 사용한 경우보다 성능 향상을 보이지 못했다.
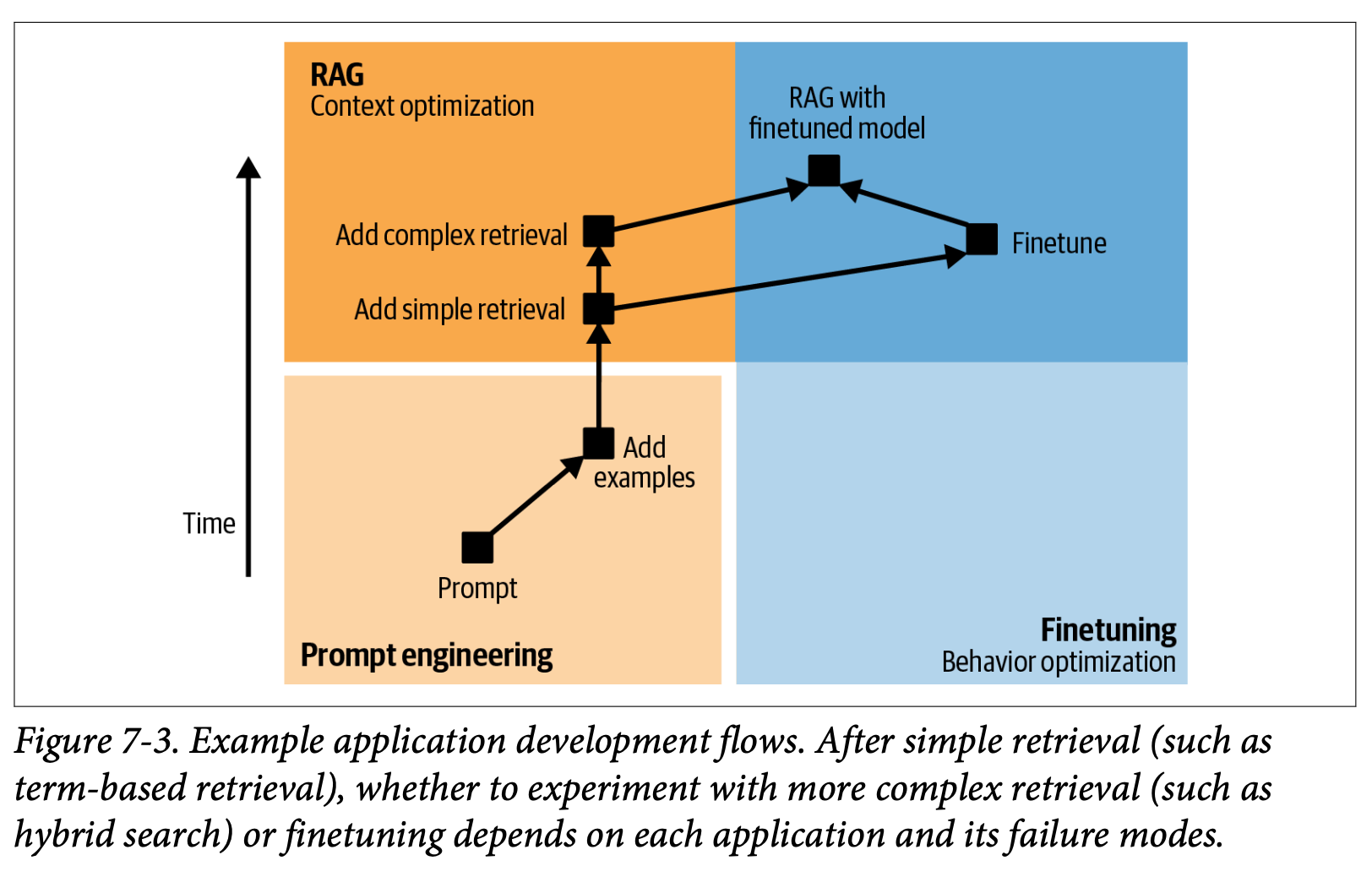
- 모델의 적응 과정은 아래처럼 요약할 수 있다.
- 프롬프트만으로 작업을 수행할 수 있는 모델을 구하려고 시도한다. 프롬프팅 시 체계적인 버전 관리를 수행한다.
- 프롬프트에 예제를 더 추가한다. 예제는 대개 1에서 50개 정도다.
- 정보 부족으로 자주 실패하면 RAG를 도입하고, 용어 기반 검색부터 시도한다. 간단한 조회retrieval만으로도 적절하고 정확한 지식 제공으로 모델의 성능 향상을 이끌 수 있다.
- 모델의 실패 방법에 따라 아래를 시도한다.
- 정보 부족으로 인한 실패 시 임베딩 기반 검색과 같은 고급 RAG 방법을 RAG에 도입한다.
- 행동 문제(부적절하거나 형식이 틀리거나, 불안전한 답변)가 있다면 파인튜닝을 선택할 수 있다.
- 임베딩 기반 검색은 추론의 복잡도를 높히는 반면, 파인튜닝은 모델의 개발의 복잡도를 높히고 추론은 유지한다.
- RAG와 파인튜닝을 결합해 성능을 더 향상시킨다.
메모리 병목
파인튜닝은 메모리 집약적이어서 많은 파인튜닝 기술들이 메모리 발자국을 최소화하는 것을 목표로 하고 있다.
역전파와 학습 파라미터
- 파인 튜닝의 메모리 사용량에서 핵심 요소는 학습 파라미터trainable parameters의 수다. 학습 파라미터는 파인튜닝 중 업데이트되는 파라미터를 의미한다. 변하지 않는 파라미터는 고정 파라미터frozen parameters라고 한다.
- 현재 신경망은 대개 역전파backpropagation 메커니즘으로 훈련된다.
- 역전파는 훈련을 2가지 단계로 구분한다.
- 순방향 전달forward pass: 입력으로부터 출력을 계산하는 과정
- 역방향 전달backward pass: 순방향 전달로부터 집계된 신호를 이용해 모델의 가중치를 수정하는 과정
- 역전파는 훈련을 2가지 단계로 구분한다.
- 추론은 순방향 전달만 수행한다. 훈련은 두 과정 모두 수행한다.
- 거시적 관점에서 역전파는 아래와 같은 작업을 수행한다.
- 정과정에서 계산된 출력과 기대 출력(실제 참값)을 비교한다. 두 출력의 차이는 손실loss라 한다.
- 각 학습 파라미터가 얼마나 실수에 기여했는지 계산한다. 기여도는 그라디언트gradient이라고 한다. 수학적으로 그라디언트는 손실을 각 학습 파라미터에 따라 편미분한 값으로 계산된다.
- 학습 파라미터를 각 그라디언트에 따라 조정한다. 각 그라디언트 값에 따라 각 파라미터가 얼마나 재조정되는지는 옵티마이저optimizer에 의해 결정된다. 흔한 옵티마이저는 SGDstochastic gradient descent와 Adam이다. 트랜스포머 기반 모델은 Adam이 현재 가장 많이 쓰이는 옵티마이저다.
- 역전파 외의 유망한 훈련 접근법은 Maheswaranathan el al.이 제안한 근사 그라디언트와 랜덤 탐색을 결합한 진화적 전략evolutionary strategy이다.
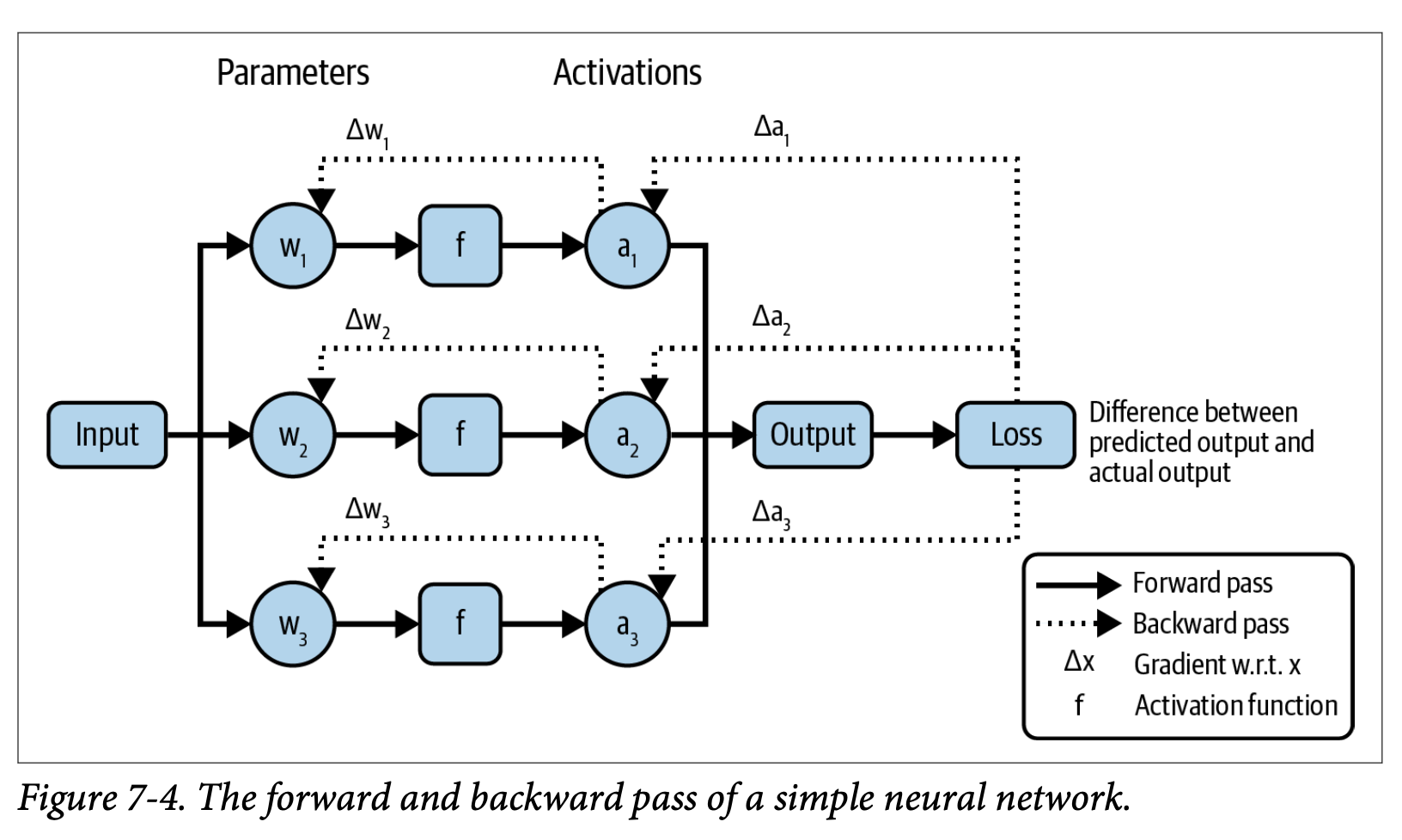
- 역방향 전달 시 학습 파라미터는 그라디언트와 옵티마이저 상태라는 추가적인 값과 함께 존재하게 된다.
메모리 계산
모델에 필요한 메모리량을 알면 적합한 하드웨어를 선택할 때 유용하다.
추론에 필요한 메모리
- 추론에는 순방향 전달만 수행된다.
- 모델의 파라미터 수를 \(N\), 각 파라미터에 필요한 메모리량을 \(M\)이라하면 모델의 파라미터를 불러오는 데 필요한 메모리량은 아래와 같다.
- 순방향 전달 시 활성화 값activation values를 위한 메모리도 필요하다. 트랜스포머 모델은 어텐션 메커니즘을 위한 키-벨류 벡터를 담을 메모리가 필요하다. 이는 시퀀스 길이와 배치 사이즈에 따라 선형적으로 증가한다.
- 많은 앱에서 활성화와 키-벨류 벡터를 위한 메모리는 모델의 가중치 메모리의 20%로 가정할 수 있다.
- 컨텍스트 길이나 배치 크기가 더 크다면 실제 메모리 사용량은 더 높을 수 있다.
- 가정에 따른 메모리 사용량은 아래와 같다.
- 13B 파라미터 모델, 파라미터 당 2 바이트라고 가정하면 13B * 2 bytes = 26GB의 가중치 메모리가 필요하다. 추론에 필요한 총 메모리양은 26GB * 1.2 = 31.2GB다.
훈련에 필요한 메모리
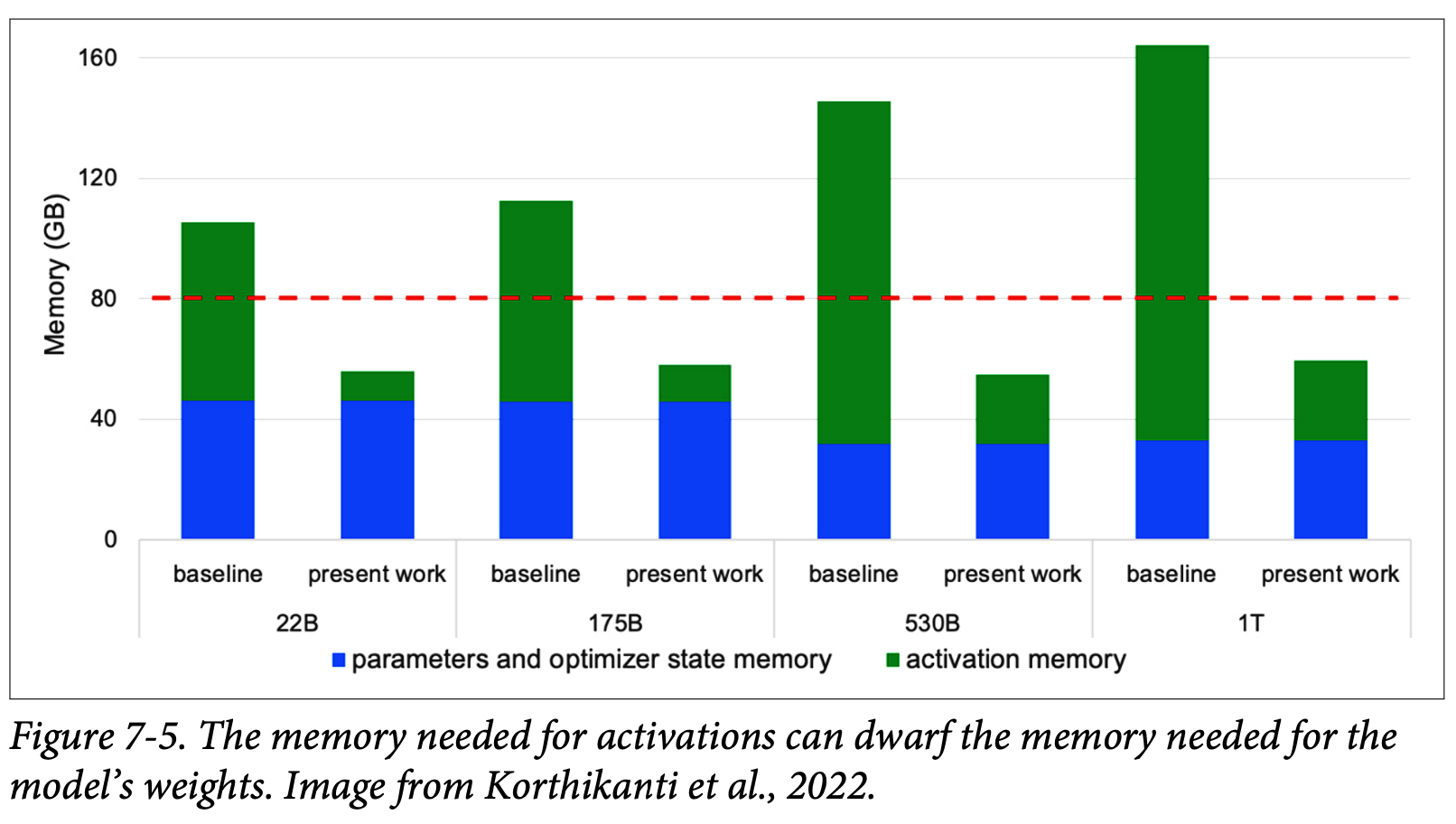
- 모델을 훈련하려면 모델의 가중치와 활성화 값, 그라디언트와 옵티마이저 상태를 위한 메모리가 필요하다.
- 13B 파라미터 모델을 생각해보자. Adam 옵티마이저 사용 시 각 학습 파라미터는 그라디언트와 옵티마이저 상태를 위한 세 개의 값이 필요하다. 각 값을 저장하는데 2 바이트가 필요하다면 필요한 메모리량은 아래와 같다.
- 위 계산에선 활성화에 필요한 메모리량이 모델의 가중치에 필요한 메모리보다 매우 적다고 가정했따. 현실에선 활성화 메모리가 훨씬 클 수 있다.
- 활성화에 필요한 메모리량을 줄이기 위한 한 방법은 활성화 값을 저장하지 않는 것이다. 이는 그라디언트 체크포인팅gradient checkpointing 또는 활성화 재계산activation recomputation이라고 불린다. 이것이 메모리 요구량을 줄일 수 있지만 재계산으로 인해 훈련에 필요한 시간이 증가할 수 있다.
수 표현Numerical Presentations
- 신경망의 숫자 값은 전통적으로 부동소수점 숫자float numbers로 표현됐다.
- 가장 일반적인 부동소수점 형식은 FP 계열로, 이는 전기전자기술자협회(IEEE) 부동소수점 연산 표준(IEEE 754)를 준수한다.
| Format | Size | Precision Level |
|---|---|---|
| FP32 | 32bits(4bytes) | Single precision |
| FP64 | 64bits(8bytes) | Double precision |
| FP16 | 16bits(2bytes) | Half precision |
- FP64는 NumPy와 pandas같은 라이브러리의 기본 형식이다.
- 신경망에서는 FP64의 많은 메모리 요구량으로 인해 FP32, FP16가 더 일반적이다.
- AI 작업 부하에서 다른 인기있는 부동소수점 형식은 BF16(BFloat16)과 TF32(TensorFloat-32)다. BF16은 TPU에서 AI 성능을 최적화하기 위해 구글이 설계했고, TF32는 GPU를 위해 NVIDIA가 설계했다.
- 수 표현은 정수를 표현할 수도 있다. 일반적인 정수 형식은 INT8(8비트 정수), INT4가 있다.
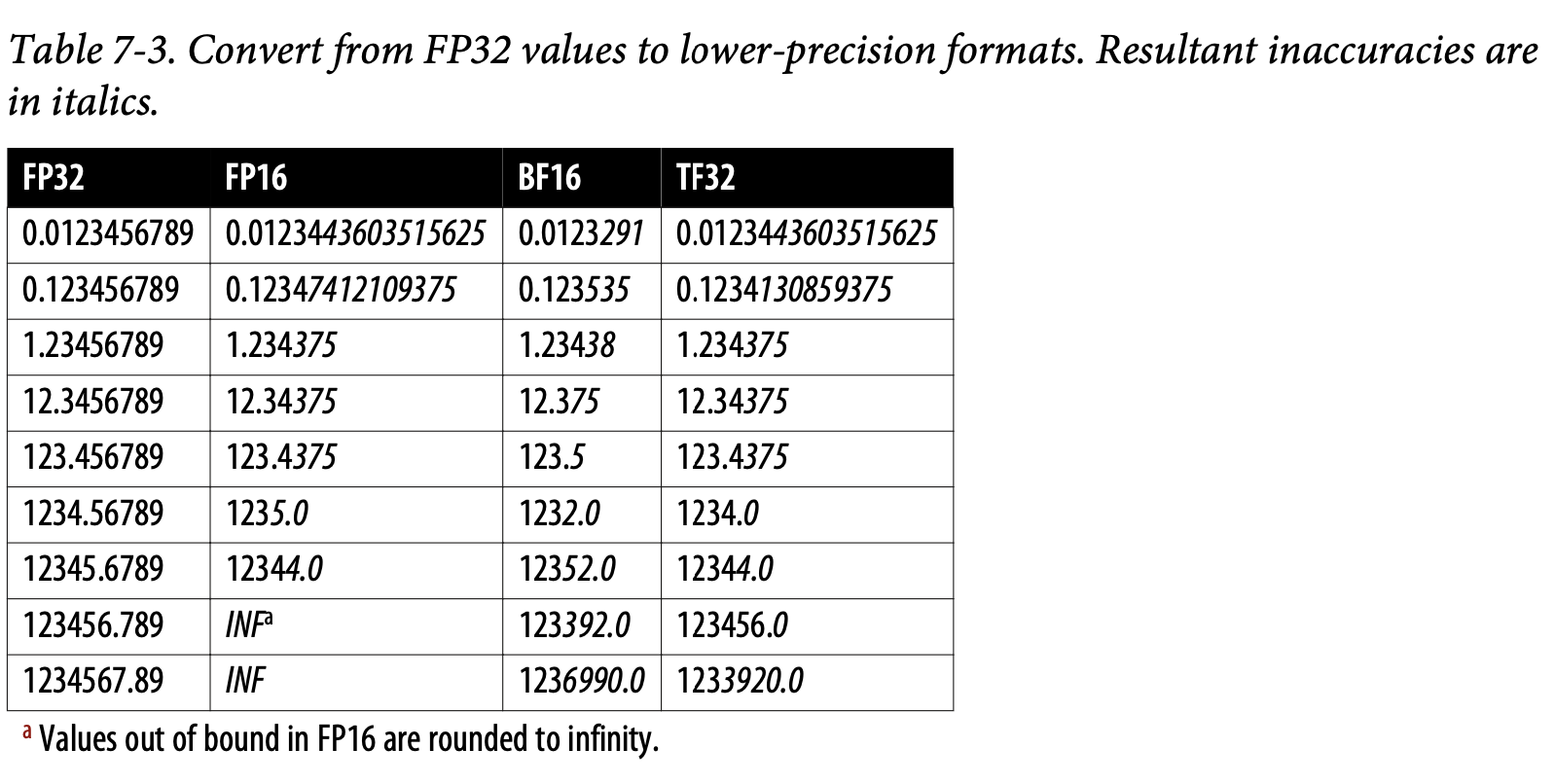
- 각 부동소수점 형식은 1비트를 숫자의 부호(양음)를 저장하는데 사용한다. 나머지 비트들은 범위range와 정밀도precision로 나뉜다.
- 범위range: 형식이 표현할 수 있는 값의 범위를 결정
- 정밀도precision: 숫자가 얼마나 정밀하게 표현되는지 결정. 10.12는 10.1234보다 덜 정밀함

양자화Quantization
- 모델의 값을 표현하는데 적은 비트가 필요할수록 메모리 발자국도 낮아진다.
- 정밀도를 낮추는 양자화는 모델의 메모리 발자국을 저렴하고 극적으로 효과적으로 줄이는 방법이다.
- 양자화를 수행하기 위해서는 무엇을, 언제해야하는지 결정해야한다:
- 양자화할 것: 모델의 성능을 크게 해치지 않는 요소를 양자화할 수 있다. 가중치 양자화는 활성화 양자화보다 일반적이다. 가중치 양자화가 더 적은 정확도 감소를 통해 성능에 안정적인 영향을 미치는 경향이 있기 때문이다.
- 언제 양자화 하는가: 양자화는 훈련 중 또는 훈련 후 가능하다. 훈련 후 양자화post-straining quantization(PTQ)는 모델이 완전히 훈련된 뒤 모델을 양자화하는 것이다. 현재 PTQ가 가장 일반적이다. 모델을 훈련하지 않는 AI 앱 개발자에게 적합하다.
추론 양자화
- 딥러닝 초기엔 FP32으로 모델 훈련 및 서빙을 했다.
- 2010년대 후반이후 16비트나 더 낮은 정밀도로 모델을 서빙하는 게 일반화됐다.
- Dettmers et al. (2022)는 LLM.int8()로 8비트, Dettmers et al. (2023)는 QLoRA로 4비트의 양자화를 훌륭하게 구현했다.
- 모델은 혼합 정밀도로 서빙될 수 있다.
- Apple (2024)은 기기에서 직접 모델을 서빙하기 위해 2-bit, 4-bit 혼합의 평균 3.5-bit-per-weight를 사용했다.
- NVIDIA는 4-bit 부동소수점 추론을 지원하는 Blackwell (2024) GPU 아키텍처를 발표했다.
- 일반적으로 파라미터 값은 INT8, INT4 같은 정수형으로 양자화된다.
- Ma et al. (2024)은 BitNet b.158을 통해 1비트 LLM 시대를 진입함을 선언했다. 이는 3.9B 파라미터까지 16-bit Llama2 성능과 견줄만하다.
- 정밀도 감소는 메모리 발자국을 줄이고 계산 속도로 개선할 수 있다.
- 더 큰 배치 사이즈를 가능하게 하고, 모델이 더 많은 입력을 병렬로 처리할 수 있게 한다.
- 감소된 정밀도는 계산을 가속하고 추론 지연과 훈련 시간을 줄인다.
- 정밀도 감수의 단점은 각 변환이 종종 작은 값 변화를 유발하고 많은 작은 변화가 큰 성능 변화를 야기할 수 있다는 것이다.
- PyTorch, TensorFlow, HuggingFace의 트랜스포머를 비롯한 주요 ML 프레임워크는 코드 몇 줄로 가능한 PTQ을 무료로 제공한다.
- TensorFlow Lite나 PyTorch Mobile 같은 기기 내 추론을 위한 프레임워크도 PTQ를 제공한다.
훈련 양자화
- 훈련 중 양자화는 PTQ보다 일반적이지 않지만 점차 인기를 끌고 있다.
- 훈련 양자화의 2가지 서로다른 목표:
- 추론 동안 낮은 정밀도로 좋은 성능을 내는 모델을 생산한다.
- 훈련 시간과 비용을 줄인다.
- 양자화 인지 훈련Quantization-aware training(QAT)은 추론에서 낮은 정밀도로 높은 품질을 보이는 모델을 만드는 것을 목표로 한다.
- QAT는 훈련 동안 모델이 낮은 정밀도 동작을 시뮬레이션하여 낮은 정밀도에서 고품질 출력을 생산하는 방법을 배울 수 있게 한다.
- QAT는 계산이 여전히 고정밀도에서 수행되기 때문에 모델의 훈련 시간을 감소시키지 않는다.
- QAT는 저정밀도 행동을 시뮬레이션하느라 더 많은 작업을 수행해 훈련 시간을 증가시킬 수 있다.
- 저정밀도로 모델을 직접 훈련시키면 두 목표를 이루는데 도움이 될 수 있다.
- Character.AI (2024)는 모델 전체를 INT8로 훈련해 훈련, 서빙간 정밀도 부조화를 줄이고 훈련 효율성을 크게 높혔다. 하지만 저정밀도 훈련은 어려운데, 역전파가 저정밀도에서 더 민감하기 때문이다.
- 저정밀도 훈련은 혼합 정밀도에서 종종 이루어지는데, 가중치는 고정밀도로 유지하고 그라디언트나 활성화 같은 다른 값은 저정밀도로 유지하는 방법이 있다. 덜 민감한 가중치 값은 저정밀도로 계산하고 더 민감한 가중치는 고정밀도로 계산할 수도 있다.
- 많은 ML 프레임워크에서 제공되는 automatic mixed precision (AMT) 기능은 저정밀도가 될 수 있는 모델의 부분을 자동으로 설정한다.
- 훈련의 다른 단계에서는 다른 정밀도 수준을 사용할 수 있다. 모델은 고정밀도로 훈련된 후 저정밀도로 파인튜닝될 수 있다.
파인튜닝 기술
- PEFT을 중심으로한 메모리 효율적인 파인튜닝 기술을 주로 살펴본다.
- 모델을 사용자화하기 위해 실험적인 방법인 모델 병합도 알아본다.
파라미터 효율적인 파인튜닝Parameter-Efficient Finetuning
- 전체 모델을 파인튜닝하는 것은 전체 파인튜닝full finetuning이라한다.
- 기술이 파라미터 효율적이라는 것은 전체 파인튜닝보다 적은 규모의 학습 파라미터로 유사한 성능을 달성할 수 있다는 것을 의미한다.
- PEFT는 Houlsby et al., 2019에 의해 소개되어, 모델의 올바른 위치에 추가적인 파라미터를 삽입하면 적은 훈련 파라미터로 강력한 파인튜닝 성능을 달성할 수 있음을 보였다.
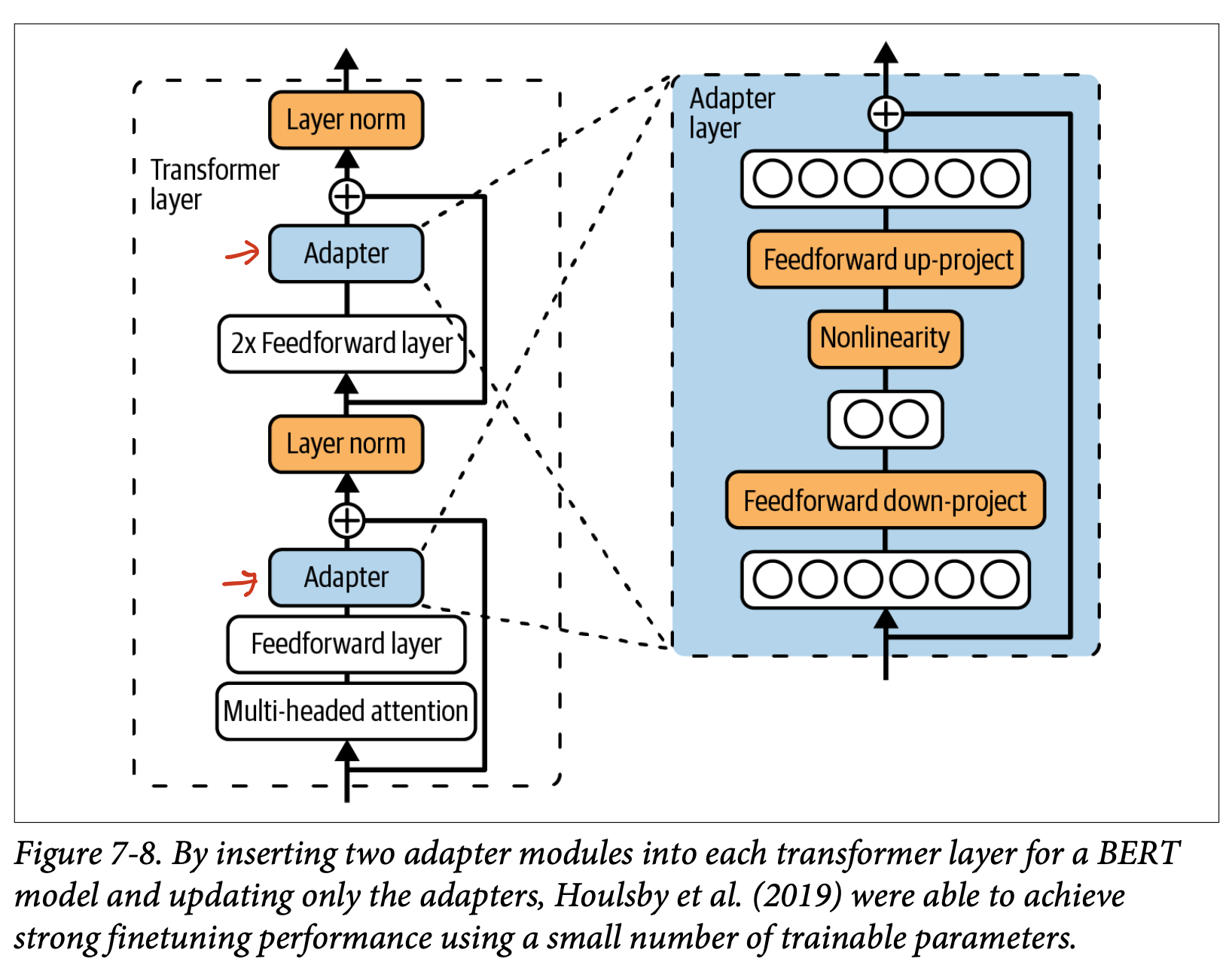
- PEFT 동안 모델의 본래 파라미터는 고정한채 어댑터adapters만 새롭게 수정한다. 훈련 파라미터는 어댑터 파라미터 수다.
- PEFT의 단점은 파인튜닝한 모델의 추론 지연을 증가시킨다는 점이다. 어댑터가 추가적인 레이어를 도입하여, 순방향 전달 시 추가적인 계산 단계를 만들고 추론을 느리게한다.
PEFT 기술
- PEFT는 주로 2가지 방법으로 나뉜다: 어댑터 기반adapter-based과 소프트 프롬프트 기반soft prompt-based 방법
- 어댑터 기반 방법은 모델 가중치에 추가적인 모듈을 도입하는 모든 방법이다.
- 소프트 프롬프트는 사람이 읽기 어려운 연속적인 벡터 형태의 프롬프트로 모델의 행동을 교정한다.
LoRA
- LoRALow-Rank Adaptation (Hu et al., 2021)는 추가적인 추론 지연 없이 새로운 파라미터를 융합하는 방법이다.
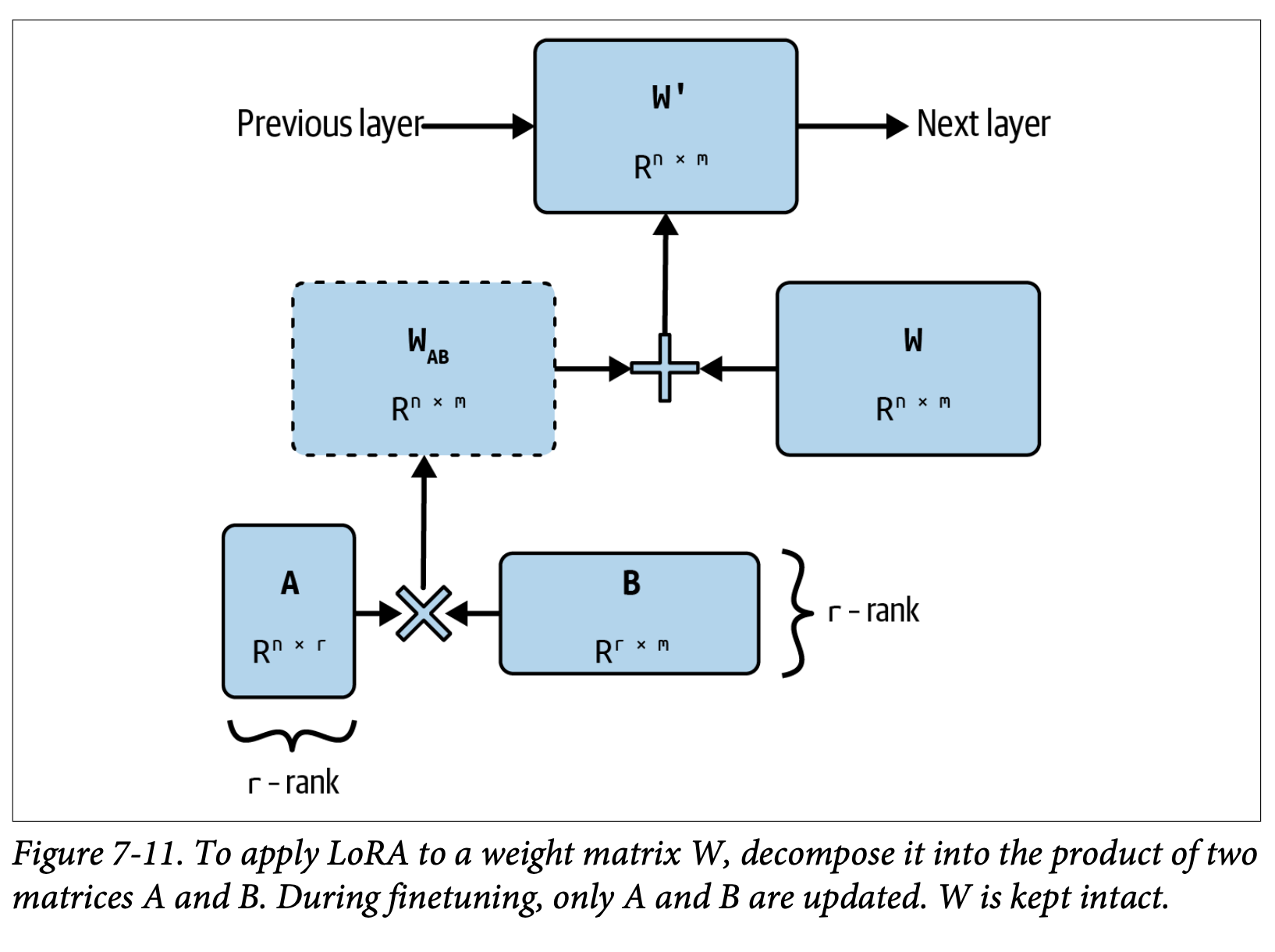
- 가중치 행렬 \(W\)의 차원이 \(n \times m\)일 때, LoRA의 동작은 다음과 같다:
- 새로 만들 작은 행렬들의 차원을 선택한다. LoRA rank인 \(r\)을 선택하면 2개의 행렬을 만들 수 있다. \(A\)(차원 \(n \times r\))과 \(B\)(차원 \(r \times m\))이다. 두 행렬의 곱은 \(W_{AB}\)로 \(W\)와 동일한 차원을 가진다.
- \(W_{AB}\)를 본래 가중치 행렬인 \(W\)에 더해 새로운 가중치 행렬 \(W'\)을 만든다. \(W'\)를 \(W\) 자리에 모델의 일부로 위치시킨다. 하이퍼파라미터 \(\alpha\)를 사용해 \(W_{AB}\)가 새로운 행렬에 얼마나 영향을 미칠지 설정할 수 있다. \(W' = W + {\alpha \over r} W_{AB}\)
- 파인튜닝에서 오직 \(A, B\)의 파라미터만 새롭게 수정한다. \(W\)는 유지한다.
LoRA가 동작하는 이유
- 많은 논문에서 LLM은 많은 파라미터를 지니지만, 매우 적은 내재 차원을 지닌다는 점을 주장한다. (Li et al., 2018, Aghajanyan et al., 2020, Hu et al.,
2021)
- 이는 사전 학습이 암무적으로 모델의 내재 차원을 최소화한다는 것을 보여준다.
- 더 큰 모델은 사전 학습 후 더 낮은 내재 차원을 지니는 경향이 있다.
- 사전 학습은 하류 작업을 위한 압축 프레임워크처럼 동작한다고 볼 수 있다.
- LLM이 더 잘 훈련될수록, 더 적은 수의 훈련 파라미터와 더 적은 양의 데이터로 파인튜닝을 더 쉽게 수행할 수 있다.
LoRA 설정
- LoRA을 적용하려면 어떤 행렬에 LoRA를 적용하고 각 인수 분해에 어떤 rank를 적용할지 결정해야한다.
LoRA 어댑터 서빙하기
- 일반적으로 LoRA로 파인튜닝한 모델을 2가지 방법으로 서빙된다.
- 파인튜닝 모델 서빙 이전에 LoRA 가중치 A, B를 원본 모델에 병합해 새로운 행렬 W’를 만든다. 추론 과정에서 추가 연산이 없으므로 추가 지연도 없다.
- 서빙 과정에서 W, A, B를 분리하여 유지한다. 추론 과정에서 W로 A, B 행렬 병합이 이루어지고 추가 지연을 유발한다.
- 첫 번째 선택지는 하나의 LoRA 모델만 있을 때 적합하다.
- 두 번째 선택지는 여러 LoRA 모델을 서빙할 때 낫다. 여러 LoRA 모델을 동일 베이스 모델을 공유한 채 서빙할 수 있다.
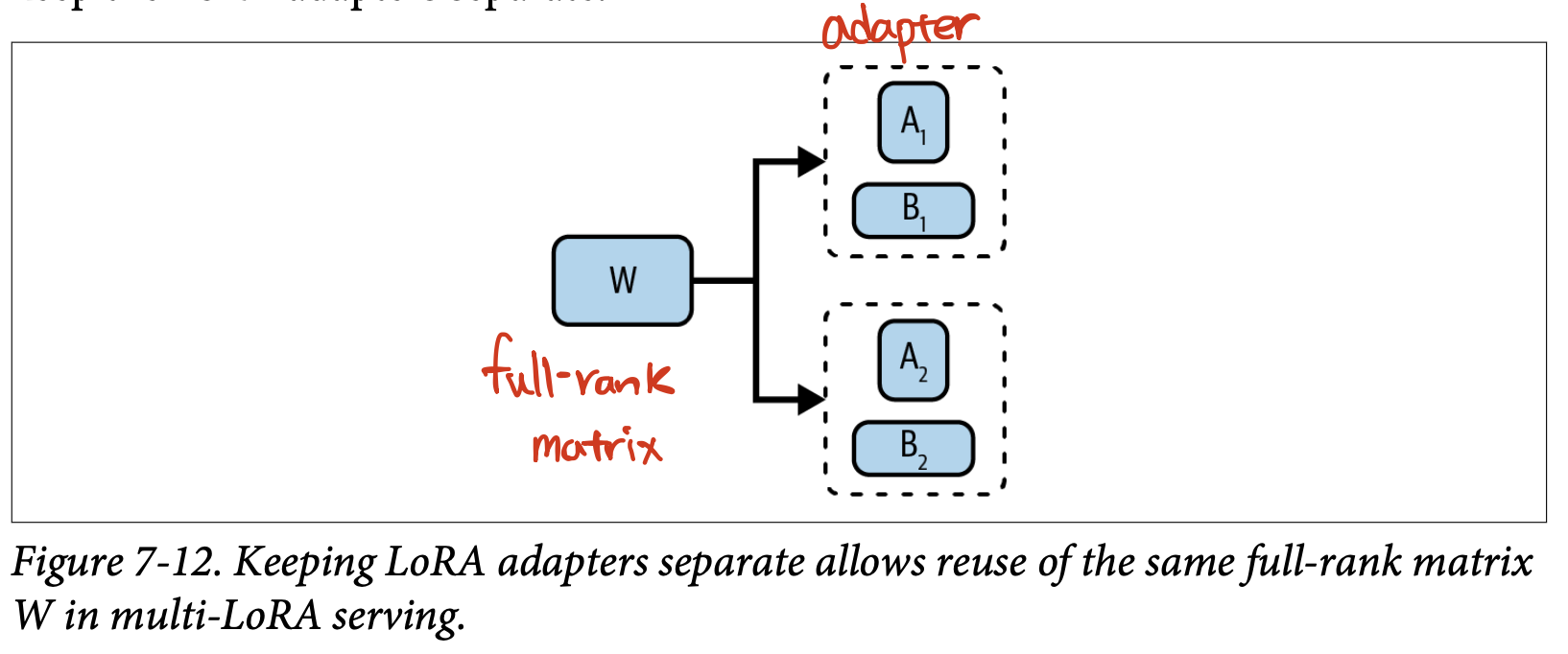
- 다중 LoRA 서빙 시 두 번째 선택지는 추론 지연을 늘리지만 현저하게 저장소 요구량을 줄일 수 있다.
- 100명의 고객을 위한 100개의 파인튜닝 모델이 있을 경우 첫 번째 선택지에서는 100개의 full-rank 행렬 W’를 저장해야한다. 두 번째 선택지에서는 하나의 full-rank 행렬 W를 저장하고 100개의 작은 행렬 (A, B)를 저장한다.
- 두 번째 선택지는 작업간 교체를 빠르게 할 수 있다. 전체 가중치를 새롭게 불러오지 않고, 새로운 모델의 LoRA 어댑터만 불러와 로딩 시간을 현저하게 줄일 수 있다.
모델 병합과 다중 작업 파인튜닝
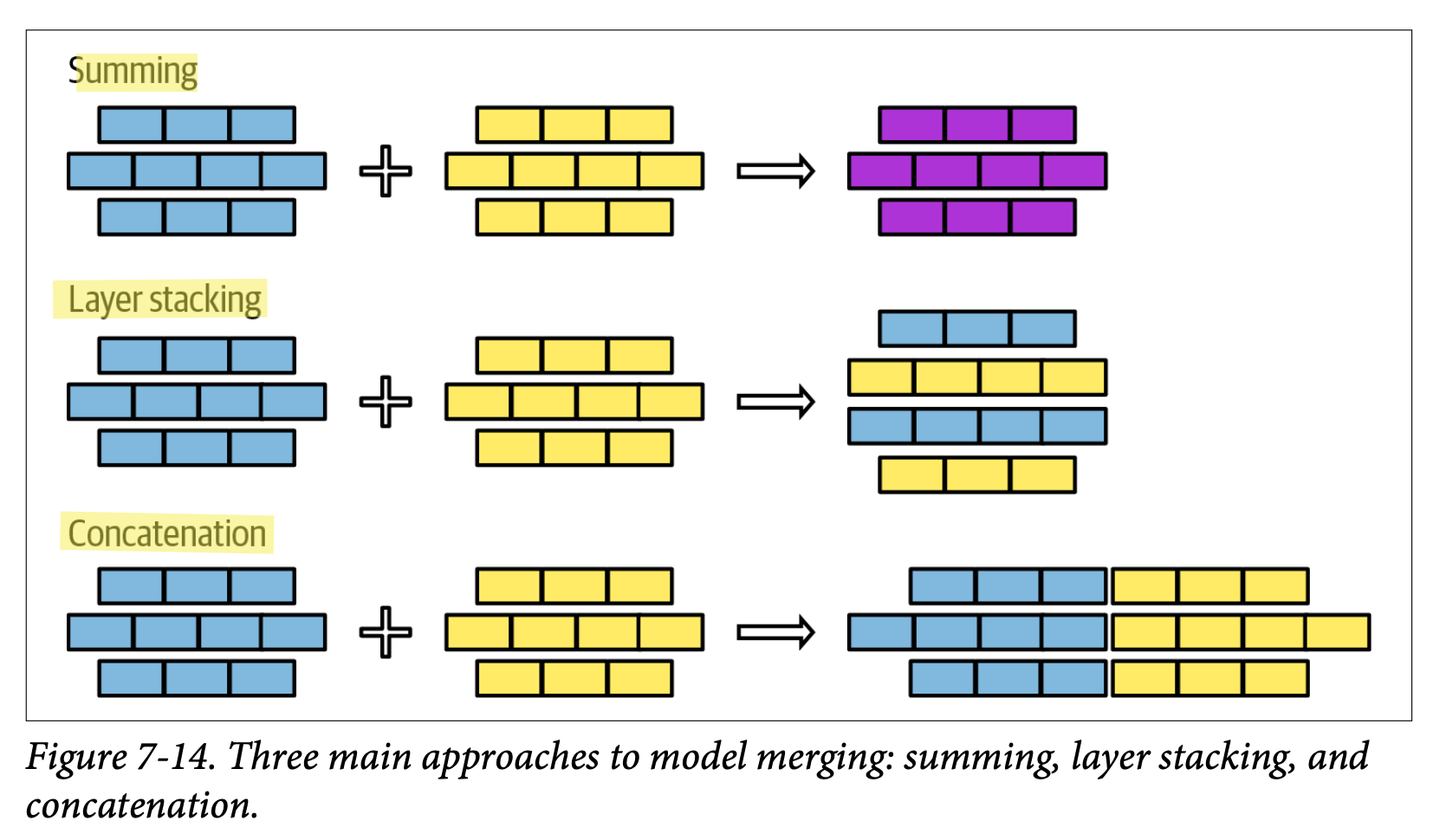
파인튜닝 전략
요약
Chatper 8
Dateset Engineering: 데이터셋 엔지니어링
- 모델의 품질은 훈련 데이터의 품질에 의존한다.
데이터 선별Data Curation
- 올바른 데이터는 모델을 더 유능하게, 안전하게, 더 긴 컨텍스트를 다룰 수 있게 한다.
- 데이터 선별은 모델이 어떻게 학습하는지, 학습에 도움이 되는 가능한 자원이 어떤 것인지에 대한 이해가 필요한 과학이다.
- 필요한 데이터는 하고자 하는 작업과 어떤 걸 모델에 가르치고 싶은지에 달려있다.
- 자기 지도 파인튜닝을 위해서는 데이터 시퀀스가 필요하다.
- 지시 파인튜닝을 위해서는 (지시, 응답) 형식의 데이터가 필요하다.
- 선호도 파인튜닝을 위해서는 (지시, 이긴 응답, 진 응답) 형태의 데이터가 필요하다.
- 보상 모델을 위해서는 선호도 파인튜닝과 같은 형태의 데이터를 이용하거나 ((지시, 응답), 점수) 형태의 주석 처리된 점수 데이터를 이용한다.
- 훈련 데이터는 모델이 학습하기를 원하는 행동을 나타내야 한다.
- CoT와 논리적 사고reasoning를 모델에 가르치는 건 복잡하다.
- Chain-of-Thought: 모델이 단계별 응답을 생성하도록 가르치려면 훈련 데이터가 CoT 응답을 포함해야 한다. Chun et al., 2024는 파인튜닝 데이터에 단계별 응답을 합치는 것이 CoT 작업에 대한 다양한 사이즈의 모델이 큰 성능 향상을 이룬다는 것을 보였다. 일부는 특정 작업에 대해 두 배의 정확도를 보였다.
- 다단계 응답을 만들어내는 건 지루하고 시간 소모적일 수 있다.

- 이로 인해 CoT 데이터셋은 다른 지시 데이터셋에 비해 흔하지 않다.
- 다단계 응답을 만들어내는 건 지루하고 시간 소모적일 수 있다.
- Tool use: 사전 학습에서 획득한 많은 양의 지식으로 많은 모델은 본능적으로 어떤 도구를 사용할 지 알 수 있다.
- 모델의 도구 사용 능력은 도구 사용 예시를 보여줌으로써 향상할 수 있다.
- 도구 사용 데이터를 만들어내는 데에는 도메인 전문가를 이용하는게 일반적이다. 각 프롬프트는 도구 사용을 필요로 하는 작업이며, 응답은 작업을 수행하기 위해 필요한 동작이다.
- 사람이 작업을 어떻게 수행하는지 관찰하는 것은 정확성을 위해 종종 필요하다.
- AI 에이전트의 도구 사용 방식은 사람과 다를 수 있으므로 도구 사용 데이터 생성은 많은 경우 시뮬레이션과 합성 기술에 의존한다.
- Dubey et al., 2024에서 Llama 3 저자들은 다중 메시지 채팅 형식을 설계했다. 이는 각 메시지의 출발지와 도착지를 구체화하는 메시지 헤더, 그리고 사람과 AI 순서가 어디서 시작되는지 구체화하는 특별한 종료 토큰으로 구성되어있다.
- Chain-of-Thought: 모델이 단계별 응답을 생성하도록 가르치려면 훈련 데이터가 CoT 응답을 포함해야 한다. Chun et al., 2024는 파인튜닝 데이터에 단계별 응답을 합치는 것이 CoT 작업에 대한 다양한 사이즈의 모델이 큰 성능 향상을 이룬다는 것을 보였다. 일부는 특정 작업에 대해 두 배의 정확도를 보였다.
- 대화형 인터페이스의 앱을 위해 데이터 선별을 하려면 single-turn, multi-turn 데이터 또는 둘다 필요한지 고려해야한다.
- single-turn 데이터는 개별 지시에 응답하도록 모델을 훈련할 수 있다.
- multi-turn 데이터는 모델이 작업을 해결하도록 가르칠 수 있다. 많은 실제 세계의 작업은 상호교환적인 과정을 포함하기 때문이다. 예로, 주어진 질의에 대해 모델은 작업을 해결하기에 앞서 사용자의 의도를 명확히해야할 수 있다. 모델 응답 이후, 사용자는 다음 단계를 위해 수정이나 추가 정보를 제공할 수 있다.
- multi-turn 데이터는 종종 이를 포착하기 위해 목적에 맞게 설계된 시나리오나 더 복잡한 상호작용을 필요로 한다.
- 데이터 선별은 모델이 새로운 행동을 배우도록 새로운 데이터를 만드는 것뿐만 아니라 모델이 나쁜 행동을 배우지 않도록 존재하는 데이터를 제거하는 과정도 포함한다.
- 거시적 관점에서 데이터 선별은 데이터 품질, 데이터 포괄성, 데이터 양의 3가지 기준에 따른다.
데이터 품질
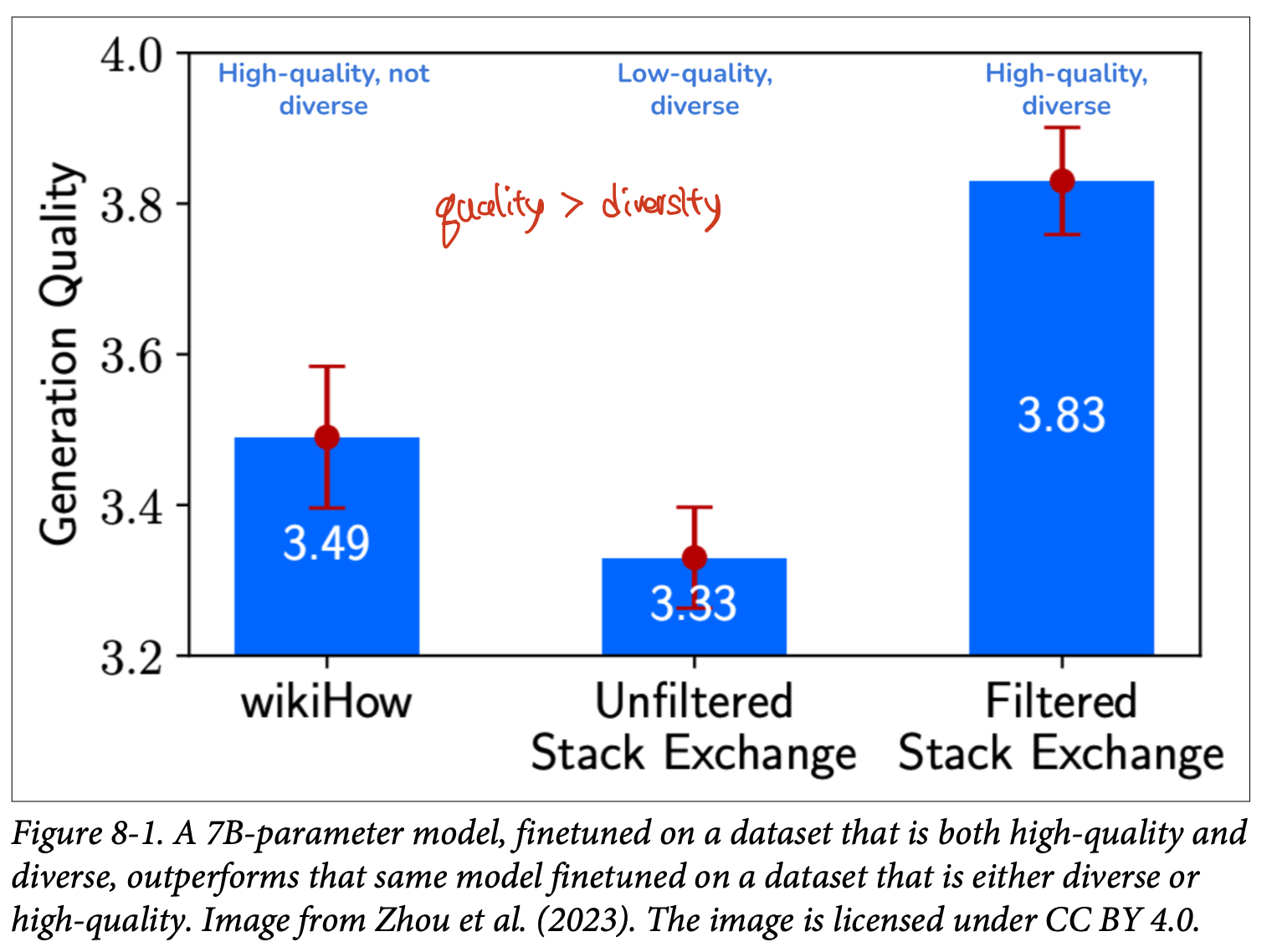
- 적은 양의 고품질 데이터는 많은 양의 잡음 가득한 데이터보다 좋은 성능을 낼 수 있다.
- LIMA: Less Is More for Alignment는 65B 파라미터 Llama 모델을 섬세하게 선별한 프롬프트와 응답 1,000개를 이용해 파인튜닝해, 사용자들로부터 GPT-4보다 43%의 경우 선호되게 만들었다. 하지만 너무 적은 예제는 LIMA가 제품 수준의 모델만큼 강건robust하지 않게 만들었다.
- Llama 3 팀은 고품질에 대한 확신을 위해 AI 보조 주석 도구를 개발했다.
- 데이터에 있어 고품질이란 작업을 효율적이고 믿을 수 있게 수행하도록 도움을 줄 수 있는 성질이다.
- 데이터의 고품질 여부는 6가지 특성을 따른다: 관련성, 작업 요구 사항과의 정합성, 일관성, 올바른 형식, 고유성, 규정 준수
- 관련성relevant: 학습 예제는 모델이 수행하려는 작업과 관련있어야 한다.
- 작업 요구 사항과의 정합성aligned with taask requirements: 주석은 작업 요구 사항과 정합해야한다. 작업이 사실적 일관성을 필요로 하면, 주석도 사실적으로 옳아야한다.
- 일관성consistent: 주석은 예제와 데이터 주석가annotators 간에 일관적이어야한다.
- 올바른 형식correctly formatted: 모든 예제는 모델이 예상하는 형식을 준수해야 한다.
- 고유성unique: 데이터에 포함된 고유한 예제 수가 많아야한다. 모델 훈련에 있어서 중복 데이터는 편견을 만들고 데이터 오염을 발생시킬 수 있다.
- 규정 준수compliant: 데이터는 법과 규제를 포함하여 내외부 정책을 준수해야한다.
데이터 포괄성Data Coverage
- 모델의 훈련 데이터는 모델이 해결해야할 문제의 범위을 포괄해야한다.
- 포괄성은 충분한 데이터 다양성을 요구한다.
- 사용자 질의에 흔히 오타가 있다면, 오타가 있는 예제를 포함해야 한다.
- 다른 앱은 다른 차원의 다양성을 지닌다. 예로, 프랑스-영어 번역 도구는 언어 다양성이 필요하지 않지만, 주제와 길이 및 발화 양식 다양성을 지녀야한다.
- 챗봇 같은 범용 용례의 경우, 파인튜닝 데이터는 넓은 범위의 주제와 발화 유형을 포함하도록 다양해야한다.
- Adler et al., 2024에서 NVDIA 연구자들은 작업, 주제 및 지시 다양성을 지니고 다른 출력 형식, 다른 출력 길이, 열린 결말 응답과 예-아니오 응답을 포함한 데이터셋을 만드는데 집중했다.
- Shen et al., 2024에서는 일부 경우, 이질적인 데이터를 더할 수록 성능이 악화되는 걸 발견했다.
- Llama 3의 성능 향상은 훈련 규모 증가 뿐만 아니라 주로 데이터 품질과 다양성에 의한 것이었다. 해당 논문에서 기술된 사전 훈련, 지도 파인튜닝, 선호도 파인튜닝에 따른 데이터 포괄성 상세의 데이터 혼합을 보는 것은 유용하다.
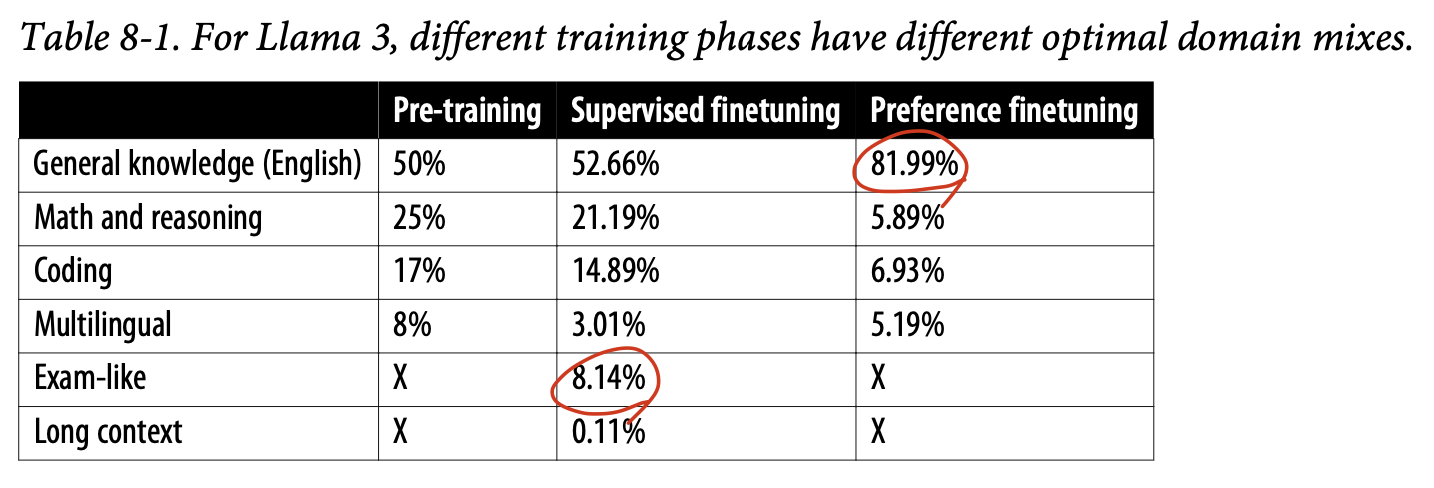
- Llama 3의 또다른 다양성 차원은 사람이 생성한 데이터와 AI가 생성한 데이터의 비율이다.
- 고품질의 코드와 수학 데이터는 자연어 텍스트보다 모델의 논리적 사고 능력을 향상시키는데 효과적이다.
- 선호도 파인튜닝의 데이터 혼합은 사용자의 실제 선호 분포에 따라 코드와 수학 데이터가 더 적다.
- 올바른 데이터 혼합은 실제 앱 사용을 정확히 반영하는 게 좋다. 최적의 데이터 혼합을 찾기 위해 실험을 수행할 수 있다.
- 2장의 스케일링 외삽처럼 작은 모델을 특정 데이터 혼합에 따라 훈련시키고 해당 혼합에 대한 대형 모델의 성능을 예측할 수 있다.
- LIMA: Less Is More for Alignment는 데이터 다양성과 품질의 영향도를 평가했다.
데이터 양
- 필요한 데이터 양은 상황에 따라 다르다.
- Jeremy Howard와 Jonathan Whitaker는 단 하나의 예제로 LLM을 파인튜닝했다.
- 다른 팀은 백만개의 예제로 파인튜닝하기도 했다.
- 파인튜닝은 대개 사전학습 모델을 바탕으로 하는 게 효과적이지만, 훈련 데이터가 많으면 처음부터 사전학습하는 게 나을 수 있다. 이는 고착화ossification 현상으로 사전 학습이 모델 가중치를 고정시켜서 파인튜닝이 잘 진행되지 않는 현상을 의미한다. 작은 모델이 큰 모델보다 고착화에 영향받기 쉽다.
- 필요한 데이터 양은 다음 요소에 따른다:
- 파인튜닝 기술: 전체 파인튜닝이 나은 성능을 보일 수 있지만 LoRA 같은 PEFT에 비해 훨씬 많은 데이터를 요구한다.
- 작업 복잡도: 단순한 작업은 복잡한 작업에 비해 훨씬 적은 데이터를 요구한다.
- 베이스 모델의 성능: 베이스 모델의 원하는 성능에 가까울수록 적은 예제가 필요하다. 모델이 클수록 성능이 좋다고 가정하면, 대형 모델을 파인튜닝할 때는 보다 적은 예제가 필요하다.
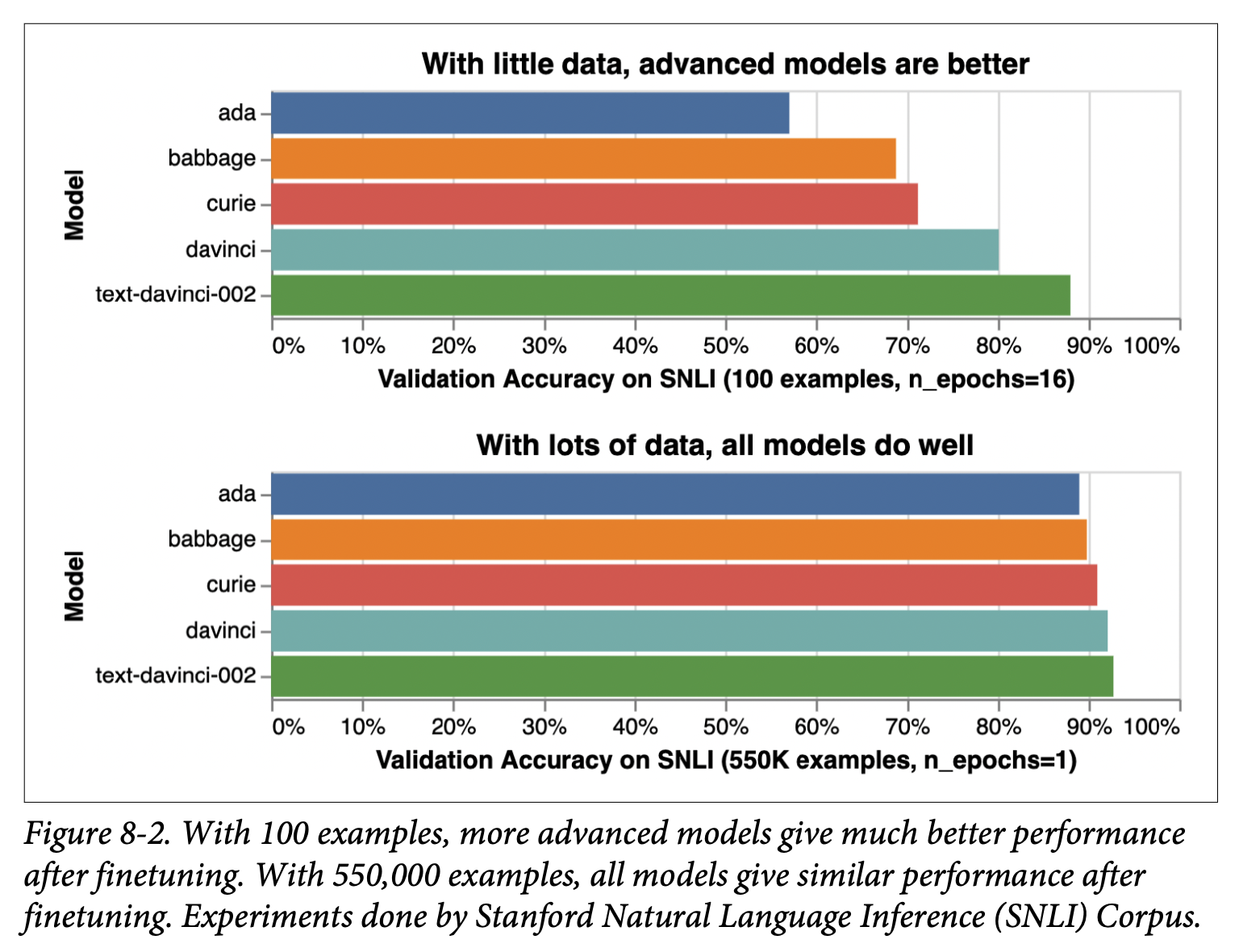
- 요약하자면, 데이터 양이 적으면 보다 고급 모델에 PEFT를 사용하는 게 낫다. 양이 많으면 작은 모델을 전체 파인튜닝하는 게 낫다.
- 적은 정교하게 만들어진 데이터셋(예를 들면, 50개 정도)을 이용해 파인튜닝이 모델을 향상시키는지 먼저 확인하라.
- 대다수의 경우 50-100개의 예제를 이용한 파인튜닝으로 성능 향상을 관찰할 수 있다.
데이터 획득과 주석Data Acquistion and Annotation
- 데이터 획득의 목표는 필요한 품질과 다양성의 데이터를 지닌 충분히 큰 데이터셋을 생산하는 것이다. 이 과정에서 데이터 관행은 사용자 개인정보를 보호하고 규정을 준수해야한다.
- 가장 중요한 데이터 출처는 대개 앱 자체에서 생성한 데이터다.
- 앱 데이터는 하고자 하는 작업에 완벽히 관련있고 정합한다는 점에서 이상적이다.
- 사용자 생성 데이터는 사용자 컨텐츠, 사용자의 사용으로 부터 생성된 시스템 데이터, 유저 피드백이 있을 수 있다.
- 자체 데이터 생성 전에 오픈 소스와 독점 데이터를 포함한 다양한 데이터 시장을 먼저 살펴보라.
데이터 증강 및 합성
- 데이터 증강data augmentation: 존재하는 실제 데이터로부터 새로운 데이터를 만드는 과정
- 데이터 합성data synthesis: 실제 데이터의 속성을 모방하는 데이터를 생성하는 과정
왜 데이터 합성을 할까?
- 데이터 품질, 포괄성, 양을 위해 데이터 합성을 한다.
- 데이터 양을 늘리기 위해
- 데이터 합성이 AI 모델의 훈련과 시험을 위한 충분한 데이터를 큰 규모로 생성할 수 있게 한다는 점이 가장 큰 이유다.
- 데이터 포괄성을 늘리기 위해
- 모델 성능을 향상시키거나 특정 행동을 표현하도록 유도하기 위해 목표한 특성을 지닌 데이터를 생성할 수 있다.
- 데이터 품질을 향상시키기 위해
- 종종 사람의 근본적인 한계로 인해 AI 생성 데이터보다 사람 생성 데이터가 저품질을 지닐 수 있다. 도구 사용이 그 예로, 사람과 AI는 동작과 도구 선호가 근본적으로 다르다.
- 개인 정보 걱정을 상쇄하기 위해
- 개인 정보 문제로 사람이 생성한 데이터를 사용할 수 없을 때 합성 데이터는 유일한 선택지다.
- 모델을 증류하기 위해
- 종종 저렴하거나 빠른 모델을 원본 모델과 견줄만한 성능으로 만들기 위해 데이터 합성을 사용한다.
전통적인 데이터 합성 기술
규칙 기반 데이터 합성
- 사전 정의된 규칙과 양식을 이용해 데이터를 생성하는 방법이다.
시뮬레이션
- 가상 환경에서 실험을 진행하여 데이터를 생성하는 방식이다.
- Waymo의 SimulationCity 같은 자율 주행 시뮬레이션이 있다.
AI 기반 데이터 합성
- AI는 특정 프로그램의 출력을 시뮬레이션할 수 있다.
- StableToolBench는 AI를 이용해 API를 실제로 호출하지 않고 시뮬레이션하는 방법을 보여준다.
지시 데이터 합성
- 지시 데이터 생성: 당신의 용례를 포괄하기 위해 다양한 주제, 키워드 및 지시 유형의 목록에 대해 지시를 합성할 수 있다.
- 답변 합성: 지시마다 1개 이상의 응답을 생성할 수 있다.
데이터 검증
- 모델 성능에 대한 데이터 품질의 중요성을 생각할 때, 데이터 품질을 검증할 방법을 갖는 것이 중요하다.
- AI 생성 데이터는 다른 AI 출력을 평가할 때처럼 기능적 올바름functional correctness과 AI 판사를 이용할 수 있다.
AI 생성 데이터의 한계
- AI 생성 데이터는 사람 생성 데이터를 완전히 대체할 수 없다. 품질 차이, 모방의 한계, 잠재적인 모델 붕괴, 불분명한 데이터 계통 때문이다.
품절 제어
겉보기 흉내
잠재적인 모델 붕괴
불분명한 데이터 계통
모델 증류Model Distillation
- 모델 증류(aka 지식 증류)model distillation는 작은 모델(학생)이 큰 모델(선생님)을 흉내내도록 훈련하는 것을 의미한다. (Hinton et al., 2015)
데이터 처리
데이터 검사
- 데이터 정보와 통계를 확인한다.
- 토큰 분포를 도표로 표현한다.
- 주제와 언어 분포를 확인한다.
- 데이터 출처, 시간, 데이터 주석가 등을 도표로 표현한다.
- 예제가 여러 주석이 있다면 주석가 간 불일치를 계산한다.
데이터 중복 제거
- 중복 데이터는 데이터 분포를 기울게하고 모델에 편견을 만들어낼 수 있다.
- 중복은 테스트 셋 오염을 유발할 수 있다.
- 중복이 모델 성능에 영향을 주지 않더라도 시간과 계산을 낭비할 수 있다.
데이터 청소 및 필터
- 모델 성능 향상과 안전성을 위해 데이터 청소가 필요하다.