Chapter 5
Prompt Engineering: 프롬프트 엔지니어링
- 프롬프트 엔지니어링은 모델이 원하는 결과를 생성하도록 지시를 만드는 과정
- 모델의 가중치를 변화시키지 않고 모델의 행동을 유도(파인튜닝과 다른 점)
- 파인튜닝처럼 자원 집약적인 기술을 도입하기 전에 프롬프트를 다듬을 필요가 있음
- 프롬프트 엔지니어링은 사람과 AI 간 소통에 관한 것
- 상용화를 위해서는 프롬프트 엔지니어링 뿐만 아니라 통계학, 엔지니어링, 전통적 ML 지식(추적, 평가, 데이터셋 선별)이 필요
프롬프트 엔지니어링 소개
- 프롬프트는 모델이 작업을 수행하게 하기 위한 지시
- 프롬프트의 일반적 구조
- 작업 정의: 모델이 수행하기 원하는 것(역할과 출력 형태 포함)
- 예제: 문장의 유해성을 판별하기 위해선 유해하거나 무해한 예제를 제시해야함
- 작업: 모델이 수행하기 원하는 구체적인 작업. 답변을 원하는 질문이나 요약하기 원하는 책을 제시

- 프롬프트가 동작하려면 대상 모델이 지시를 따르는 능력이 있어야 함
- 필요한 프롬프트 엔지니어링의 양은 모델이 프롬프트 변동perturbation에 얼마나 강건한robust지에 따라 다름
- 모델의 강건함은 프롬프트를 임의로 변동시키고 출력이 어떻게 달라지는지로 측정할 수 있음
문맥 내 학습: 제로샷과 퓨샷
- 프롬프트를 통해 모델이 어떤 일을 수행해야하는지 가르치지는 것을 문맥 내 학습in-context learning이라함
- GPT-3 논문 Language Models are Few-Shot Learners에서 소개됨
- 모델을 바람직한 행동을 프롬프트의 예제로부터 배울 수 있음. 기존에 훈련된 방식과 다르게도 가능. 가중치 업데이트는 필요 없음
- 문맥 내 학습은 모델이 새로운 정보를 지속적으로 통합하여 결정을 내릴 수 있게 하여 모델이 구식이 되지 않도록 방지
- shot: 프롬프트에 제시된 예제를 의미
- few-shot learning: 프롬프트의 예제로부터 모델이 학습하도록 가르치는 것
- 5-shot learning: 에제가 5개인 경우
- zero-shot learning: 예제가 제공되지 않는 경우
- 일반적으로 예제가 많을 수록 모델은 더 잘 배움
- 예제의 수는 모델의 최대 컨텍스트 길이에 제한됨
- 예제가 많을 수록 프롬프트가 길어지고 추론 비용이 증가함
- 모델이 강해질 수록 지시를 잘 이해하고 따르기 때문에 적은 예제로 더 나은 성능을 보여줌
- GPT-3에서 few-shot learning은 zero-shot learning에 비해 큰 향상을 보여줬음
- GPT-4 같은 이후 모델에서는 효과가 적어짐
- 도메인 특화 사용의 경우 few-shot 예제의 효과가 큼
- 모델 훈련에 사용되지 않은 예제를 제시하는 경우
- context와 prompt의 정의
- 책에서는 아래와 같이 정의함
- context: 모델에 제공된 맥락 정보
- prompt: 모델에 입력된 전문
- GPT-3 논문에서는 context와 prompt가 동일한 의미였음
- 일부 사람들은 context는 맥락 정보만을 의미한다고 주장
- 책에서는 아래와 같이 정의함
- GPT-3 이전 ML 모델들은 훈련된 내용만 수행할 수 있었기에 문맥 내 학습은 마법처럼 느껴졌음
- 프롬프트 엔지니어링은 모델이 훈련된 여러 프로그램 중 원하는 프로그램을 활성화하는 올바른 프롬프트를 찾는 과정으로 이해할 수 있음
- François Chollet이 파운데이션 모델을 여러 프로그램의 라이브러리로 비유한데서 유래
시스템 프롬프트와 유저 프롬프트
- 많은 모델 API는 프롬프트를 시스템 프롬프트와 유저 프롬프트로 나누어 입력하는 선택지를 제공
- 시스템 프롬프트는 작업 정의, 유저 프롬프트는 작업으로 생각할 수 있음

- 모델은 주어진 시스템 프롬프트와 유저 프롬프트를 하나의 프롬프트를 템플릿에 따라 결합함
- Llama 2 chat model prompt template
<s>[INST] <<SYS>> {{ system_prompt }} <</SYS>> {{ user_message }} [/INST] - 예시
<s>[INST] <<SYS>> Translate the text below into French <</SYS>> How are you? [/INST] - 모델의 chat template: 모델 개발자가 정의하는 양식(모델의 문서에서 찾을 수 있음)
- prompt template: 앱 개발자가 정의하는 양식
- Llama 3 chat model prompt template
<|begin_of_text|><|start_header_id|>system<|end_header_id|> {{ system_prompt }}<|eot_id|><|start_header_id|>user<|end_header_id|> {{ user_message }}<|eot_id|><|start_header_id|>assistant<|end_header_id|> <|와|>를 포함하는 사이의 단어는 모델에서 하나의 토큰으로 처리됨(e.g.<|begin_of_text|>)
- Llama 2 chat model prompt template
- 새 줄을 추가한 것과 같은 사소한 실수를 포함해 잘못된 템플릿을 사용할 경우 모델의 행동을 크게 변화시킬 수 있음
- 파운데이션 모델의 입력을 구성할 때 모델의 chat etmplate을 정확히 준수
- 서드파티 도구를 프롬프트 구성에 사용시 해당 도구의 오류 검증이 필수
- 모델에 쿼리를 전송하기 전 최종 프롬프트를 출력하고 이중 확인하는 것이 필요
- 잘 구성된 시스템 프롬프트는 성능 향상에 기여할 수 있음을 많은 모델 제공자가 강조함
- 내부 구조에서는 시스템 프롬프트와 유저 프롬프트가 하나의 최종 프롬프트로 합쳐서 모델로 전달됨
- 시스템 프롬프트가 성능에 더 영향을 주는 이유는 다음 요소들이 작용
- 시스템 프롬프트가 최종 프롬프트 앞단에 위치해서 먼저 나온 지시를 더 잘 처리함
- 모델이 시스템 프롬프트에 더 주의를 기울이도록 사후 학습post-trained됨
컨텍스트 길이와 컨텍스트 효율성
- 프롬프트에 얼마나 많은 정보가 포함될 수 있는가는 모델의 컨텍스트 길이 제한에 의존함
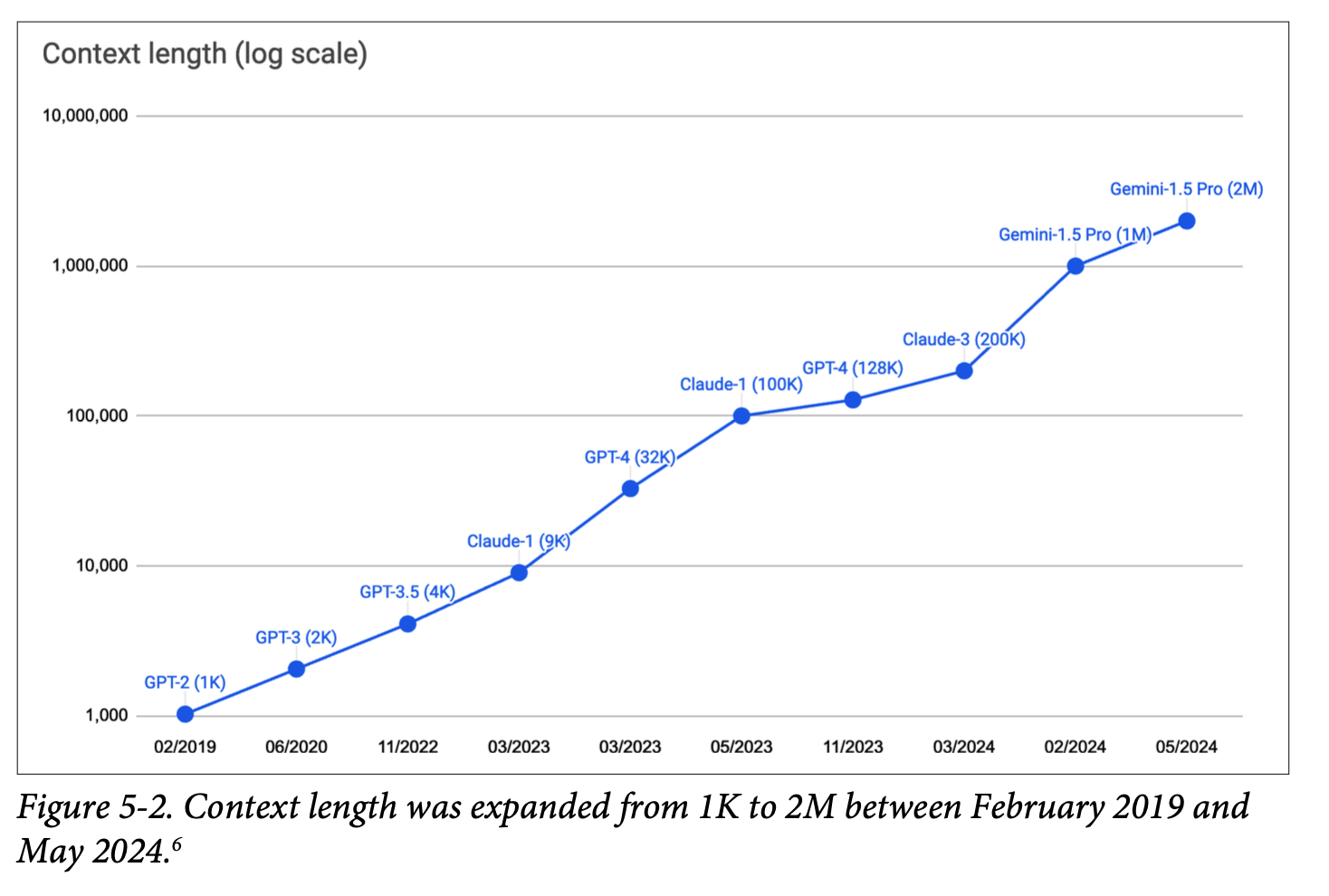
- 5년동안 GPT-2의 1K 컨텍스트 길이에서 Gemini-1.5 Pro의 2M 컨텍스트 길이로 2,000배 증가함
- 2M 컨텍스트 길이는 2,000개의 위키피디아 페이지나 PyTorch와 같은 복잡한 코드베이스를 담을 수 있음
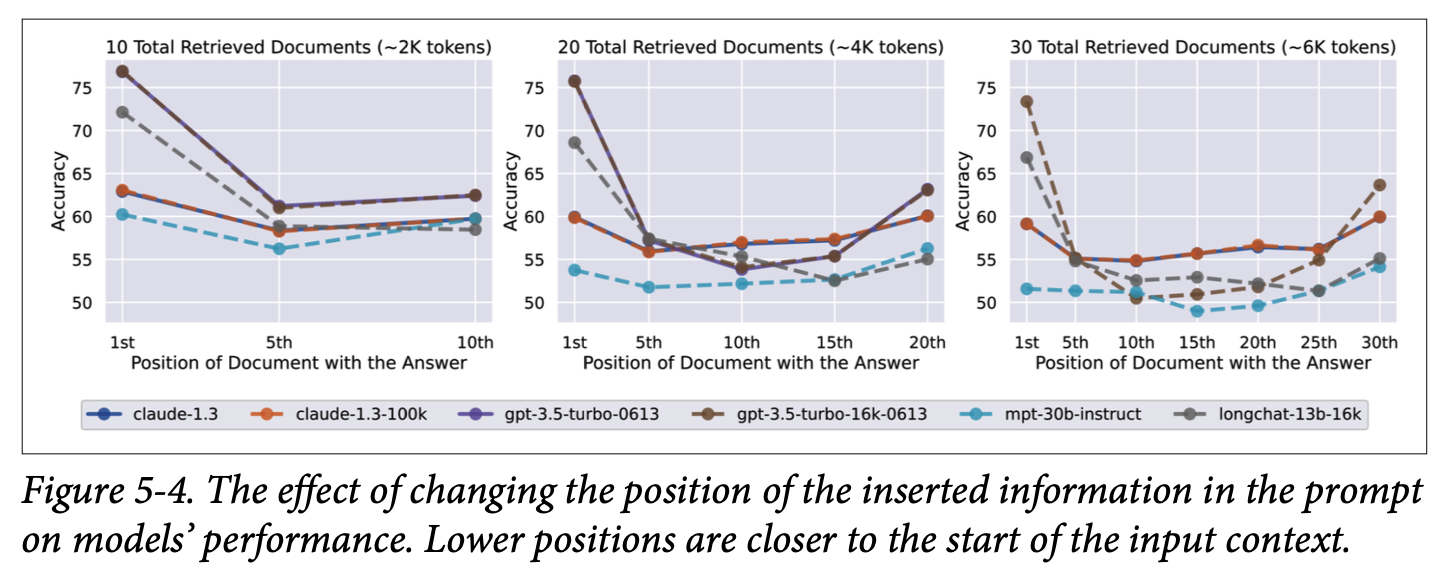
- 모델은 프롬프트의 시작과 끝 부분에 제시된 지시를 중간 부분보다 더 잘 이해함
- 프롬프트의 각 부분에 대한 효과성을 시험하는 대표적인 방법은 neeldle in a haystack(NIAH)가 있음
- 임의의 정보 조각(the needle)을 프롬프트(the haystack)의 다른 장소에 배치하고 모델에게 찾도록 요청

- 대부분의 모델은 프롬프트의 시작과 끝 부분에 있는 정보를 중간에 있는 정보보다 잘 찾아냄(정량적인 증명)
프롬프트 엔지니어링 모범 사례
- 약한 모델일수록 프롬프트 엔지니어링은 더 어려움
- “Q:” 대신 “Questions:”를 쓰거나 “올바른 답에 $300 팁”을 제안하는 것과 같은 초기 팁이 있었음
- OpenAI, Anthropic, Meta, Google의 튜토리얼을 바탕으로 작성함
명확한 지시를 작성하라
- AI와의 소통은 사람과 동일하게 명확함이 중요함
모호하지 않게 모델이 수행하기 원하는 일을 설명하라
- 에세이를 점수 매긴다면 점수 체계를 설명
- 모델이 확신할 수 없는 경우 최대한 점수를 내야하는지 “모르겠음”이라고 해야하는지 결정
모델이 페르소나를 적용하도록 요청
- 페르소나는 모델이 응답을 생성할 때 어떤 관점을 지녀야하는지 이해하는데 도움

예제 제공
- 예제는 모델이어떻게 응답해야하는가에 대한 모호함을 줄일 수 있음

- 가능하면 적은 토큰을 사용하는 예제 형식을 사용

출력 형식을 구체화
- 모델이 간결하게 응답하길 원하면 간결하게 응답하도록 명시
- 하위 앱에서 해당 모델의 응답을 활용하면 JSON과 같은 형식을 반드시 준수해야함
- 분류와 같이 구조화된 응답을 기대하는 경우 프롬프트가 끝나고 모델의 구조화된 응답이 시작되는 곳을 마킹

충분한 문맥을 제공하라
- 문맥context은 할루시네이션을 줄일 수 있음
- 필요한 정보가 제공되지 않으면 모델은 믿을 수 없는 내부 지식에 의존하여 할루시네이션을 유발할 수 있음
- 주어진 질문query에 필요한 문맥을 모으는 과정은 문맥 구성context construction이라고 함
- 문맥 구성 도구는 RAG 파이프라인과 같은 데이터 조회data retrieval와 웹검색을 포함
복잡한 작업을 하위 작업으로 나누어라
- 여러 단계를 필요로 하는 복잡한 작업의 경우, 작업을 하위 작업으로 나누어라
- 전체 작업이 거대한 하나의 프롬프트를 지니는 것이 아닌, 하위 작업이 각자의 프롬프트를 지님
- 고객 요청에 응답하는 경우 1. 의도 분류, 2. 응답 생성 과정으로 나눌 수 있음
- OpenAI의 프롬프트 엔지니어링 가이드 예시


- 실험을 통해 최적의 작업 분리와 연쇄를 찾아내야 함
- 프롬프트 분리는 성능 향상 뿐만 아니라 여러 이점이 있음:
- 모니터링: 중간 결과물을 관찰할 수 있음
- 디버깅: 각 단계를 격리하고 수정할 수 있음
- 병렬화: 독립된 단계를 동시에 실행해서 시간 단축
- 노력: 복잡한 프롬프트보다 간단한 프롬프트 작성하는 게 쉬움
- 중간 단계가 많을수록 마지막 단계 결과물의 첫 토큰을 보기까지 사용자는 더 많이 기다려야함
- 프롬프트 분리는 토큰을 적게 사용하고 API 사용 시 비용 절약면에서 유리
- 간단한 단계는 더 저렴한 모델을 사용 가능
- 작업 분리로 비용이 증가하더라도 성능과 안정성이 개선되면 가치가 있음
- GoDaddy(2024) 사례에서 고객 지원 챗봇이 1회에 1,500 토큰을 사용하는 것을 발견하고, 작은 하위 작업으로 나누어 프롬프트를 분리한 결과 모델의 성능 개선과 비용 절약을 동시에 달성
모델이 생각할 시간을 제공하라
- chain-of-thought(CoT)와 자기 비평self-critic을 사용하면 성능이 개선됨
- CoT는 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models에서 ChatGPT 출시 1년 전에 소개됨
- LinkedIn은 CoT가 모델의 할루시네이션을 줄이는 것을 발견함
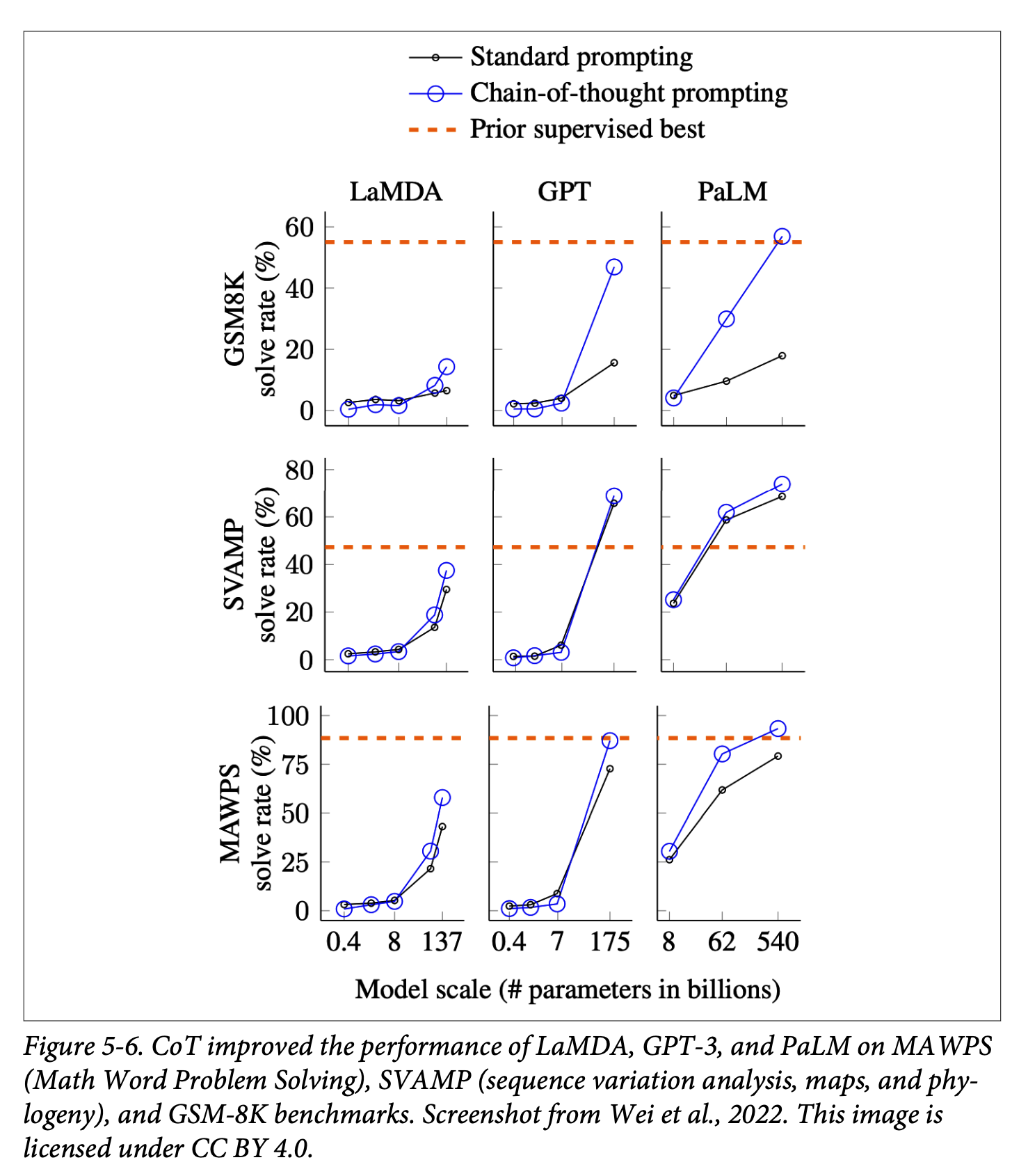
- CoT의 간단한 사용법은 아래를 프롬프트에 추가하는 것
- "think step by step" 지시
- "explain your decision" 지시
- 다른 방법으로는 모델이 수행해야할 단계를 구체적으로 제시하거나 예제를 제공하는 것

- 자기 비평self-critic의 뜻은 모델의 본인의 결과물을 확인하도록 요청하는 것
- 챕터 3의 self-eval과 동일
- 자기 비평은 모델이 문제에 대해 비판적으로 생각하도록 유도함
- 프롬프트 분리와 마찬가지로 CoT와 자기 비평은 사용자에게 인지되는 지연을 증가시킴
- 정해진 단계가 아닌 모델이 스스로의 단계를 구성하면 얼마나 지연이 될지 예상하기 어려움
프롬프트를 반복적으로 개선하라
- 모델을 잘 이해할 수록 프롬프트를 작성하는 요령이 생김
- 모델마다 특징이 다름
- 숫자를 다루거나, 역할극을 하는 것에 강점이 다름
- 프롬프트의 시작 부분과 끝 부분에 대한 집중도가 다름
- 모델 개발자가 제공한 프롬프트 가이드를 확인
- 온라인 상의 다른 사용자들의 경험을 살펴보기
- 모델 플레이그라운드가 있다면 사용하기
- 같은 프롬프트를 서로 다른 모델에 사용해보고 응답 변화를 관찰하기
- 프롬프트 버전 관리하기
- 실험 추적 도구 사용하기
- 평가 지표와 데이터를 표준화하여 서로 다른 프롬프트의 성능을 비교하기
- 전체 시스템 관점에서 각 프롬프트를 평가하기
- 어떤 프롬프트는 하위 작업을 개선하지만 전체 시스템 성능을 악화할 수 있음
프롬프트 엔지니어링 도구 평가하기
프롬프트 정리 및 버전 관리
방어적 프롬프트 엔지니어링
독점 프롬프트와 리버스 프롬프트 엔지니어링
탈옥과 프롬프트 삽입
정보 추출
프롬프트 공격에 대한 방어
요약
Chapter 6
RAG and Agents: RAG와 에이전트
- 작업을 해결하기 위해서는 지시 뿐만 아니라 필요한 정보가 제공되어야 함
- 문맥 구성context construction의 두가지 주요 패턴은 RAGretrieval-augmented generation과 에이전트agents
- RAG 패턴은 모델이 외부 데이터 소스로부터 관련 정보를 가져올retrieve 수 있도록 함
- 에이전틱agentic 패턴은 모델이 정보를 가져오기 위해 웹 검색과 뉴스 API와 같이 도구tool를 사용할 수 있도록 함
- RAG와 에이전트는 모델에 세계와 직접적으로 상호작용할 수 있는 능력을 부여하고 우리 삶의 다양한 면들을 자동화할 수 있도록 함
RAG
- RAG는 외부 기억 장소로부터 관련된 정보를 가져와서 모델의 생성을 개선시키는 기술을 의미
- retrieve-then-generate 패턴은 Reading Wikipedia to Answer Open-Domain Questions에서 처음 소개됨
- RAG라는 용어는 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks(Lewis et al. 2020)에서 제안됨
- Lewis et al.은 모델이 관련 정보에 대한 접근을 통해 보다 자세한 답변을 생성하고 할루시네이션을 줄이는데 도움을 줄 수 있음을 발견함
- 페이스북도 How Context Affects Language Models’ Factual Predictions에서 사전 학습된 언어 모델을 retrieval system을 통해 강화하면 모델의 사실 확인 질문에 대한 성능을 향상시킬 수 있음을 보여줬음
- 파운데이션 모델에서 문맥 구성context construction은 고전적 ML 모델의 피처 엔지니어링feature engineering과 동일
- 입력을 처리하기 위해 모델에 필요한 정보를 제공한다는 동일한 목적을 지님
- RAG의 종착지가 충분히 긴 컨텍스트 길이라고 생각하는 경우가 있으나 앱을 지속적으로 더 긴 컨텍스트 길이를 요구할 것
- 모델이 긴 컨텍스트를 처리하더라도 잘 이용하는지와는 별개
- 컨텍스트가 길수록 모델은 컨텍스트의 잘못된 부분에 집중할 수 있음
RAG 구조
- RAG는 2가지 요소로 구성됨
- 리트리버retriever: 외부 메모리 저장소로부터 정보를 가져옴
- 생성기generator: 가져온 정보를 바탕으로 답변을 생성
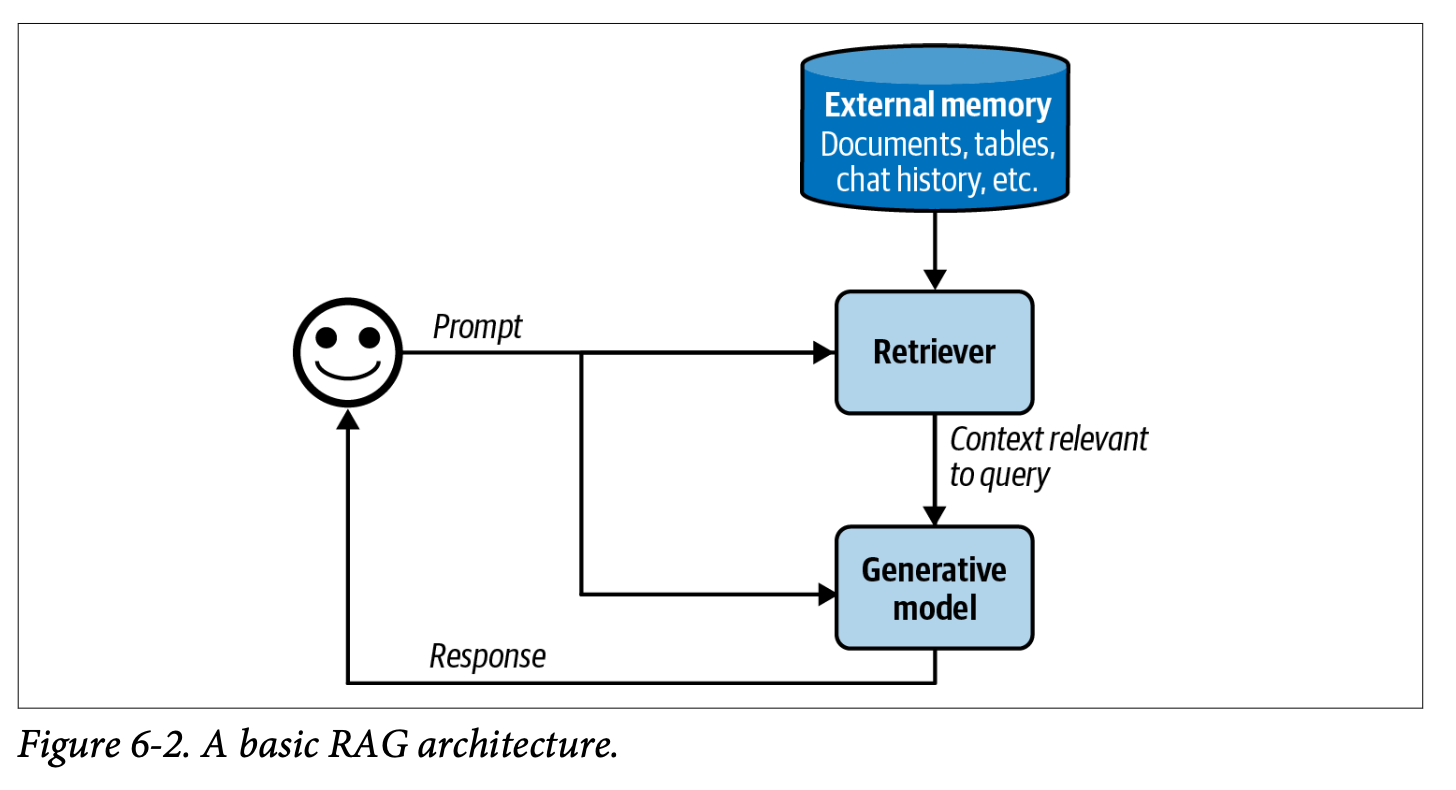
- 많은 팀이 기성 리트리버나 모델을 사용하지만 전체 RAG 시스템을 파인튜닝하면 성능을 확연히 개선시킬 수 있음
- RAG 시스템의 성공은 리트리버의 품질에 의존함
- 리트리버의 두 가지 주요 기능:
- 인덱싱indexing: 추후 데이터를 빠르게 가져올 수 있도록 데이터를 처리하는 과정
- 질의하기querying: 관련된 데이터를 가져오기 위해 질의를 호출하는 과정
- 인덱싱은 추후 데이터를 어떻게 가져오고자 하느냐에 따라 방법이 달라짐
- 문서를 처리 가능한 청크chunks로 나눌 필요가 있음
- 문서를 한 번에 가져오기엔 컨텍스트 길이가 충분하지 않을 수 있음
- 우리의 목표는 매 질의마다 관련된 데이터 청크를 가져오는 것
- 유저 프롬프트로부터 최종 프롬프트를 만들기 위해 사소한 사후 처리가 필요할 수 있음
- 최종 프롬프트는 생성형 모델에 전달됨