Chapter 3
Evaluation Methodology: 평가 방법론
평가란 무엇인가?
- 평가는 위험을 줄이고 기회를 발굴하기 위한 것
- 실패에 대한 가시성을 확보하려면 시스템을 재설계해야할 수도 있음
- 언어 모델의 평가 지표는 cross entropy, perplexity 등이 있음
- 평가는 정확도 평가와 주관적 평가가 있으며 AI 판사는 주관적 평가의 주목받는 방법임
파운데이션 모델 평가의 어려운 점
- AI 모델이 지능적이 될 수록 평가도 어려워짐
- 파운데이션 모델의 열린 선택지 특성은 전통적으로 진실에 대해 모델 평가를 하던 접근 방법을 적용하기 어렵게 하고 있음
- 대부분의 파운데이션 모델은 내부를 알 수 없음(black boxes)
- 공개적으로 가능한 평가 벤치마크는 파운데이션 모델을 평가하기 부적합한 것으로 밝혀짐
- 평가의 범위가 일반 목적 모델에 대해 넓어짐
언어 모델 지표 이해
- 언어 모델 지표에 대한 이해는 이를 이용한 다운스트림 성능을 이해하는데 도움을 줄 수 있음
- 대표적인 4가지 지표는 cross entropy, perplexity, BPC, BPB이며 서로 연관됨
- 대개 대상 데이터가 모델의 훈련 데이터와 유사할 수록 해당 데이터에 대한 모델의 성능도 높아짐
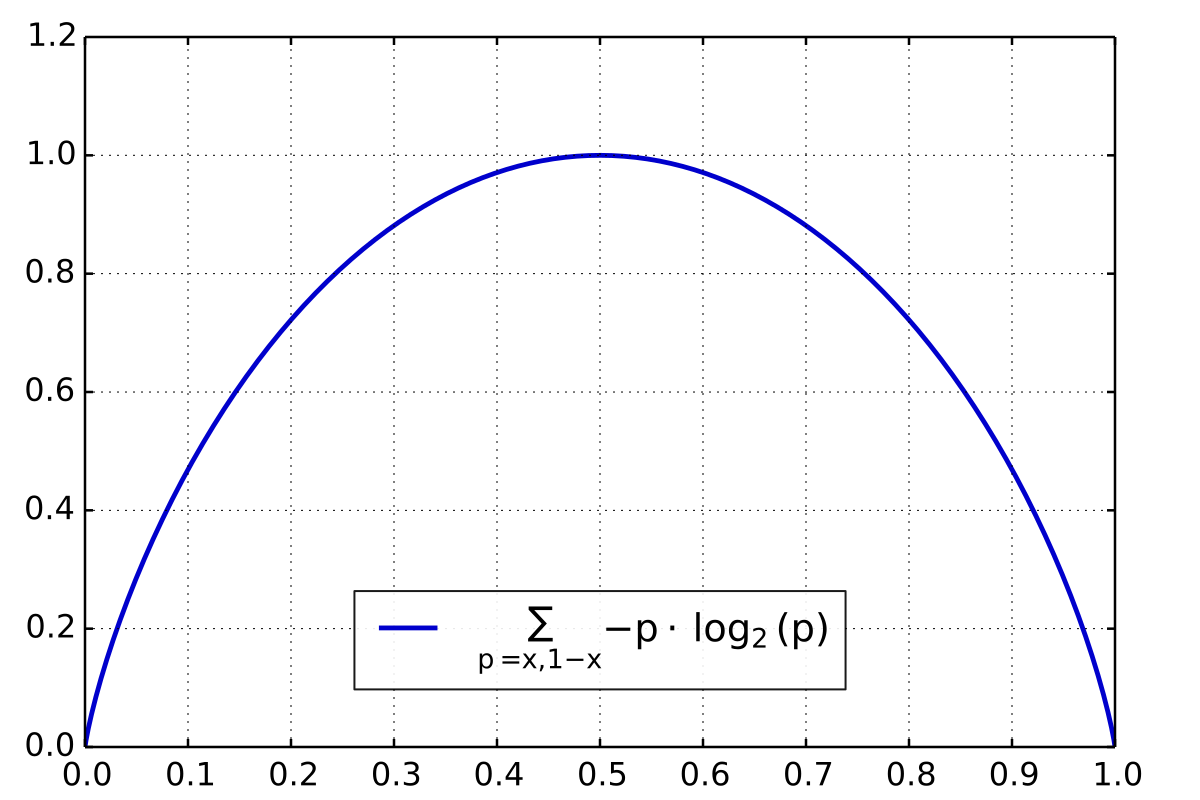
엔트로피(Entropy)
- 엔트로피는 한 토큰이 얼마나 많은 정보를 가지는지 측정하는 지표임
- 엔트로피는 다음 토큰을 예측하기 얼마나 어려운지에 대한 지표가 될 수 있음
- 다음에 어떤 토큰일지 완벽하게 예측할 수 있다면 이는 새로운 정보가 전혀 없다는 것을 의미함
- Shannon entropy
$$ H(P) = - \sum_{x} P(x) \log P(x) $$Binary Shannon Entropy
크로스 엔트로피(Cross Entropy)
- 특정 데이터 세트에 대한 언어 모델의 크로스 엔트로피는 언어 모델이 그 데이터 세트에 대한 다음 토큰을 얼마나 잘 예측할 수 있는가에 대한 지표
- 크로스 엔트로피는 2가지 특성에 의존함
- 훈련 데이터의 예측 가능성(expected 엔트로피)
- 훈련 데이터의 진짜 분포로부터 획득된 언어 모델의 분포(actual 엔트로피)
- 크로스 엔트로피는 Kullback-Leibler (KL) divergence(발산)을 통해 구할 수 있음
- KL divergence
$$ D_{\text{KL}}(P \parallel Q) = \sum_{x} P(x) \log \frac{P(x)}{Q(x)} $$ - Cross entropy
$$ H(P,Q) = H(P) + D_{\text{KL}}(P \parallel Q) = - \sum_{x} P(x) \log Q(x) $$ - 비대칭성: Q의 P에 대한 크로스 엔트로피 \(H(P,Q)\) 는 P의 Q에 대한 크로스 엔트로피 \(H(Q,P)\)와 다름
Bits-per-Character와 Bits-per-Byte
- 엔트로피와 크로스 엔트로피의 단위는 bit
- bits-per-character(BPC)는 언어 모델이 본래 훈련 데이터의 1 글자를 표현하는데 필요한 bit의 갯수
- bits-per-byte(BPB)는 언어 모델이 본래 훈련 데이터의 1 바이트를 표현하는데 필요한 bit의 갯수
- 크로스 엔트로피는 언어 모델이 텍스트를 얼마나 효율적으로 압축하는지 나타내줌
- 언어 모델의 BPB가 3.43이라면 본래 8비트를 3.43비트로 표현한 것이므로 본래 텍스트를 절반 이하로 압축
- 언어 모델의 BPB가 3.43이라면 본래 8비트를 3.43비트로 표현한 것이므로 본래 텍스트를 절반 이하로 압축
Perplexity
- Perplexity는 엔트로피와 크로스 엔트로피에 대한 지수식
- 진짜 분포 P에 대한 perplexity 정의
$$ PPL(P) = 2^{H(P)}$$ - 학습된 분포 Q에 대한 언어 모델의 perplexity 정의
$$ PPL(P,Q) = 2^{H(P,Q)}$$ - 크로스 엔트로피가 모델의 다음 토큰 예측에 대한 난이도를 측정하는 반면, perplexity는 다음 토큰 예측의 불확실성의 양을 측정함
- 불확실성이 높다는 것은 다음 토큰에 대한 가능한 선택지가 많다는 뜻
- 자연로그 nat 를 단위로 쓴다면 perplexity는 e의 지수식. TensorFlow와 PyTorch 같은 인기 ML 프레임워크는 자연 로그를 엔트로피와 크로스 엔트로피의 단위로 사용함
$$ PPL(P) = e^{H(P)}$$
Perplexity 해석과 용례
- cross entropy, perplexity, BPC, BPB는 언어 모델의 예측 정확도 지표의 종류들
- 일반적으로 perplexity는 아래와 같은 특성을 보임
- 데이터가 구조화될수록 perplexity는 감소함
- 어휘(vocabulary)가 커질수록 perplexity도 증가함
- 컨텍스트 길이가 길어질수록 perplexity는 감소함
- perplexity는 AI 엔지니어링 작업에 유용한 특성을 지님
- perplexity는 모델의 능력에 대한 좋은 대리자
- OpenAI의 GPT-2 보고서에서는 모델이 커질수록(강력할수록) 낮은 perplexity를 가짐을 보임
- 훈련 데이터의 중복 제거에 사용할 수 있음
- 새로운 데이터에 대한 perplexity가 크다면 새로운 데이터를 훈련 세트에 추가(학습되지 않았음을 유추할 수 있음)
- perplexity는 모델의 능력에 대한 좋은 대리자
- 언어 모델의 perplexity는 대개 사후 학습 후 증가하는 경향을 보임
- 언어 모델의 텍스트에 대한 perplexity 정의
$$ \text{Perplexity}(x_1, x_2, \dots, x_N) = \exp \left( - \frac{1}{N} \sum_{i=1}^{N} \log P(x_i | x_1, x_2, \dots, x_{i-1}) \right) $$$$ x_i \text{는 토큰 시퀀스의 i번째 토큰} $$
정확도 평가
- 정확도 평가는 모호하지 않은 판단을 내림
- 다지선다 문제에서 A, B 중 A가 정답인데 B를 고른다면 틀렸음을 정확히 판단할 수 있음
- 주관적 평가는 에세이 점수 평가처럼 같은 사람이라도 두 번 평가하면 다른 판단을 내릴 수 있는 평가
- AI 판사는 주관적. 모델과 프롬프트에 따라 평가 결과가 달라질 수 있음
- 정확도 평가는 크게 2가지로 나눌 수 있음
- 기능 정확도
- 기준 데이터와의 유사도 측정
기능 정확도
- 기능 정확도는 시스템이 의도된 기능성을 나타내는지 평가하는 것
- 코드 생성은 기능 정확도 측정이 자동화될 수 있는 예시
- 측정가능한 목표를 가진 작업은 기능 정확도로 평가될 수 있음
기준 데이터와의 유사도 측정
- AI의 결과를 기준 데이터와 비교
- 기준 데이터(응답)는 ground truth나 canonical responses로도 불림
- 기준이 필요한 지표는 reference-based하고 아닌 지표는 reference-free함
- 기준 데이터가 얼마나 빨리 생성되느냐가 평가의 병목